
SQLer: おそらく十分なテスト
SQLer が本番ワークロードで十分に速いかどうかを確かめておきたかった。ベンチは妥当な設計で、グラフは正しい話をしており、結果は SQLite の挙動と整合する:式インデックスは等価フィルタの性能差を解消する。正規化スキーマは大規模な更新で有利。SQLer の bulk_upsert は挿入で競争力がある。配列のメンバーシップは補助テーブルが欲しい。並行実行は SQLite の single-writer 制約に当たる。
要点: SQLer は予測可能に振る舞う。式インデックスで JSON 深度に関係なく等価検索は高速化する。バルク挿入は競争力がある。多くの行を触る更新は正規化が有利。配列検索には設計上の工夫が必要。並行性は SQLite のルールに従う。
マイクロベンチ注意:中央値が約 0.1 ms 未満の差はタイマー/Python オーバーヘッドに近く、サブミリ秒の差は厳密な小数として扱わず大まかに(≈0 ms)判断してください。
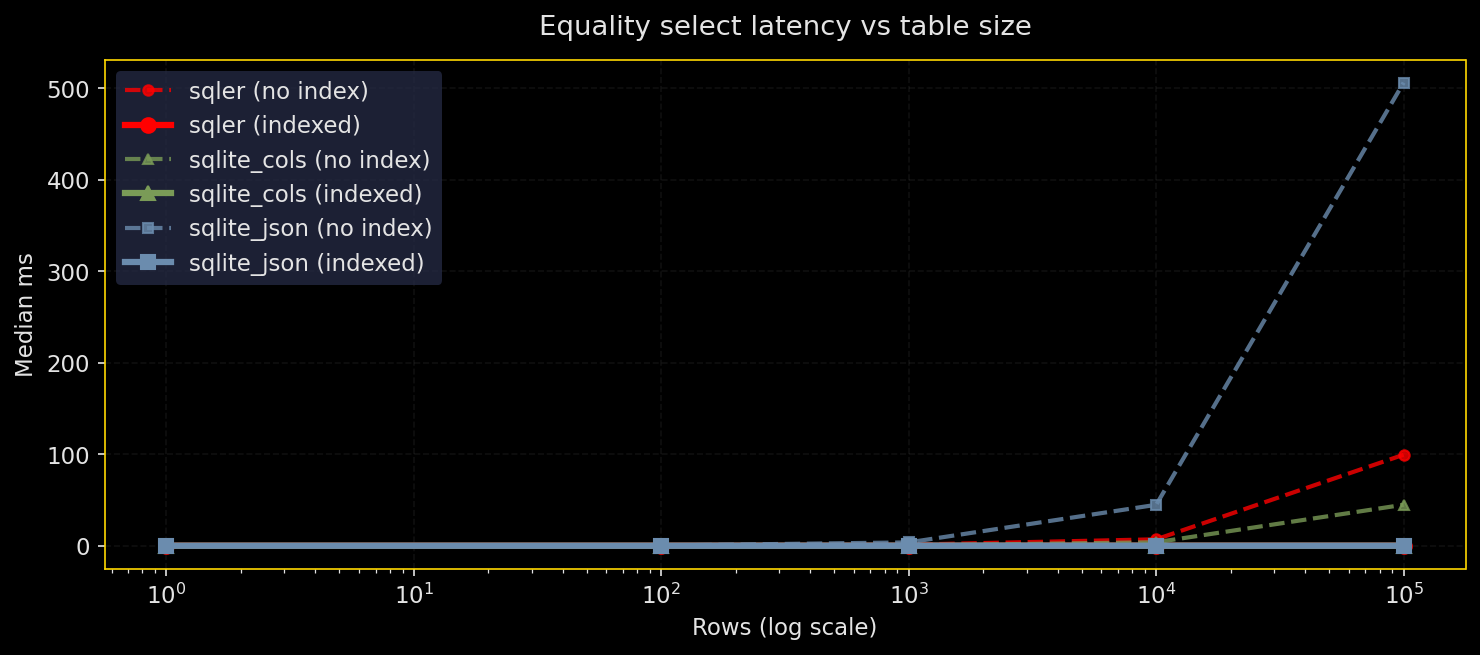
等価検索(行数と JSON 深度による差)
図:
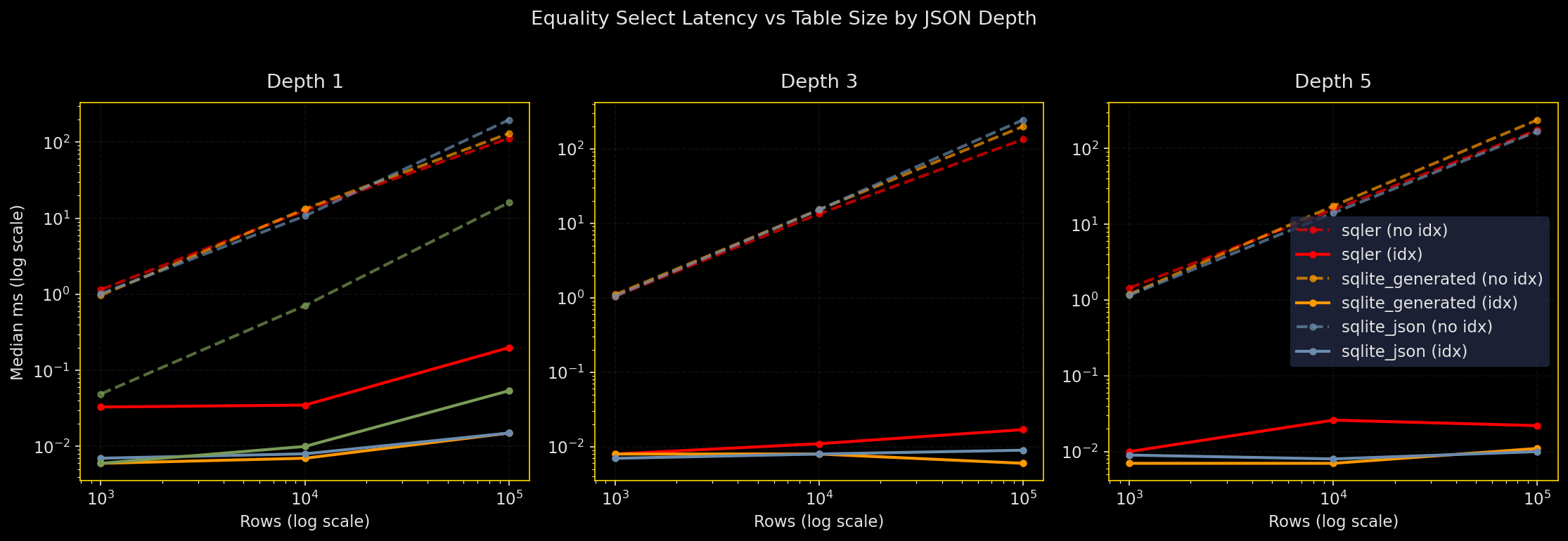
なぜテストするか:JSON フィールドに対する等価フィルタは普通に多く発生する。テーブルが大きくなり、JSON が深くなるときに SQLer は生の SQLite(JSON)や正規化カラムとどう比較されるのか?
何をするか:1K〜1M 行、JSON 深度 1, 3, 5 について同じ等価述語を実行。比較対象は SQLer(JSON ドキュメントテーブル)、生の SQLite JSON、生成カラムを使った SQLite、正規化スカラカラムの四つ。インデックス有無で比較。WAL モード、シード固定 RNG、キャッシュ温め。5 回実行し、中央値と p95 を報告。
結果:
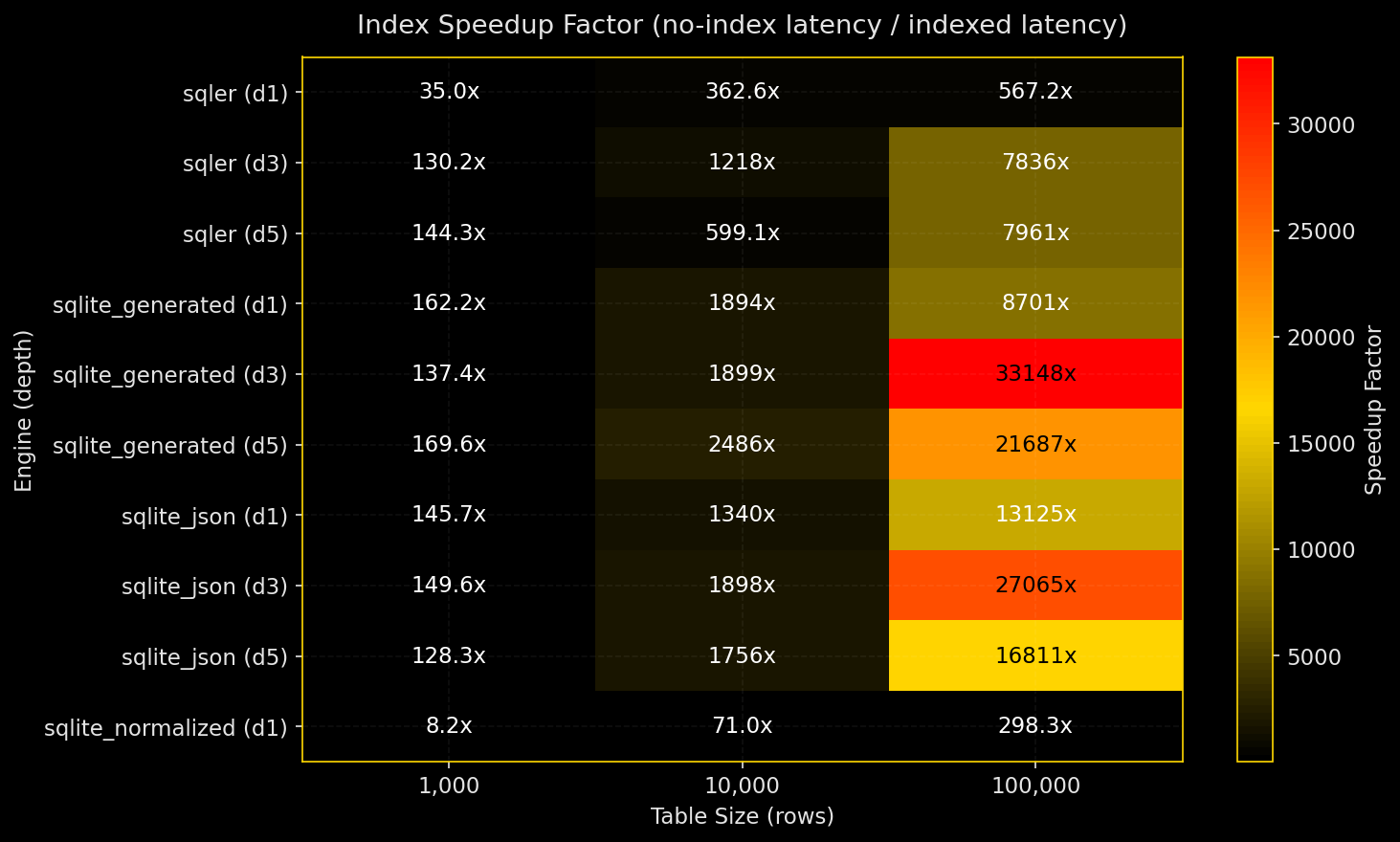
- 述語パスに式インデックスを張れば、すべてのエンジンで等価検索は高速になる
- インデックスがないと正規化カラムが有利。JSON パス評価コストが深さに応じて顕著になる
- 深い JSON パスはインデックスがないと特に遅くなる
- インデックスによる高速化は、小規模で数十倍、大規模かつ深いパスでは数千倍に達することがある
SQLer の API カバレッジ:テーブル作成(bulk_upsert)、トップレベルの等価検索(SQLerQuery.filter(F("field_0") == value))、インデックス作成(create_index("table", "field_0"))は公開 API を使用。深いパスの等価検索はまだ SQLer 側にネイティブがなく db.adapter.execute() を使って生 SQL にフォールバックしている(プロットや凡例では sqler+sql と表示)。Production guidance: 深い JSON パスの等価検索がホットなら、そのパスに式インデックスを張るか、生成カラムとしてマテリアライズしてください。
# latency_vs_size_by_depth.png の抜粋
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
fig.suptitle("Equality Select Latency vs Table Size by JSON Depth", color=TEXT, y=1.02)
for i, depth in enumerate(self.depths):
ax = axes[i]
depth_data = df[df["depth"] == depth]
for engine in sorted(depth_data["engine"].unique()):
for indexed in [False, True]:
subset = depth_data[(depth_data["engine"] == engine) & (depth_data["indexed"] == indexed)]
if len(subset) > 0:
linestyle = "-" if indexed else "--"
label = f"{engine} ({'idx' if indexed else 'no idx'})"
ax.plot(subset["n_rows"], subset["median_ms"],
color=ENGINE_COLORS.get(engine, "#666666"),
linestyle=linestyle, linewidth=2.0, alpha=0.9,
marker="o", markersize=4, label=label)
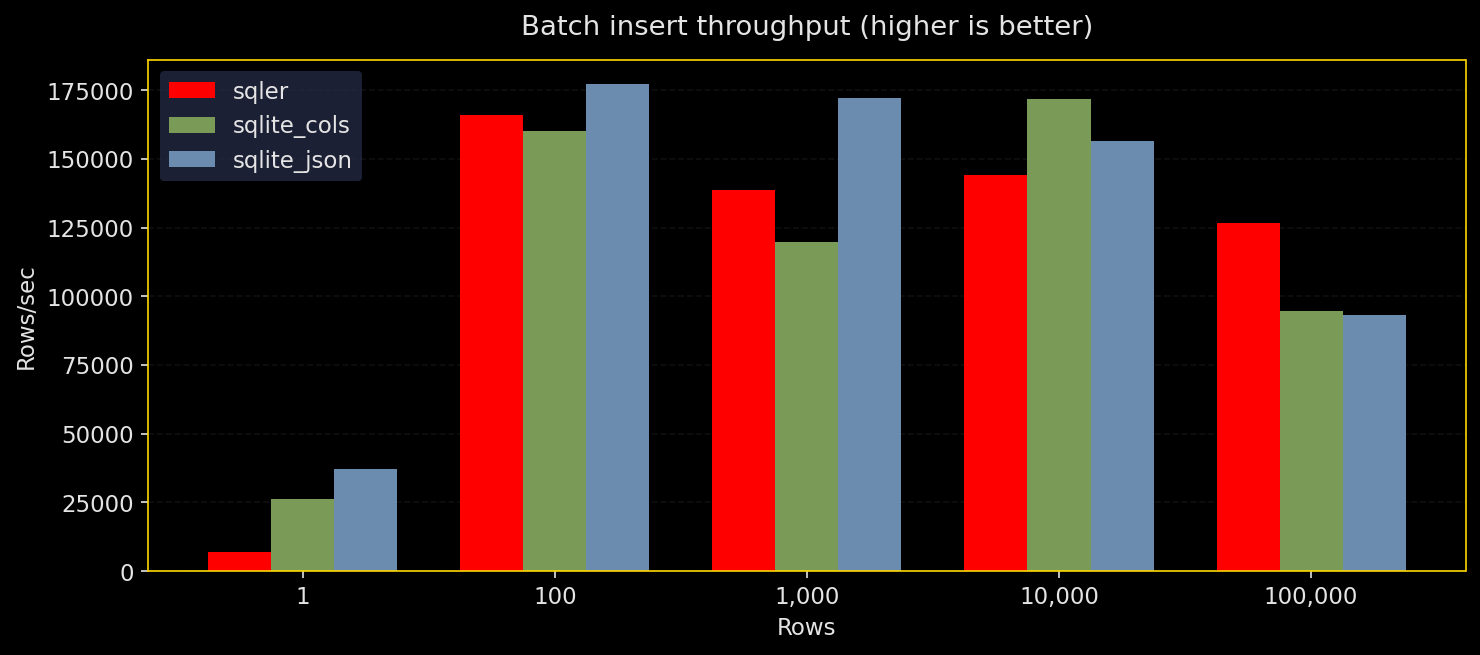
バッチ挿入:バッチサイズと耐久性によるスループット
図:
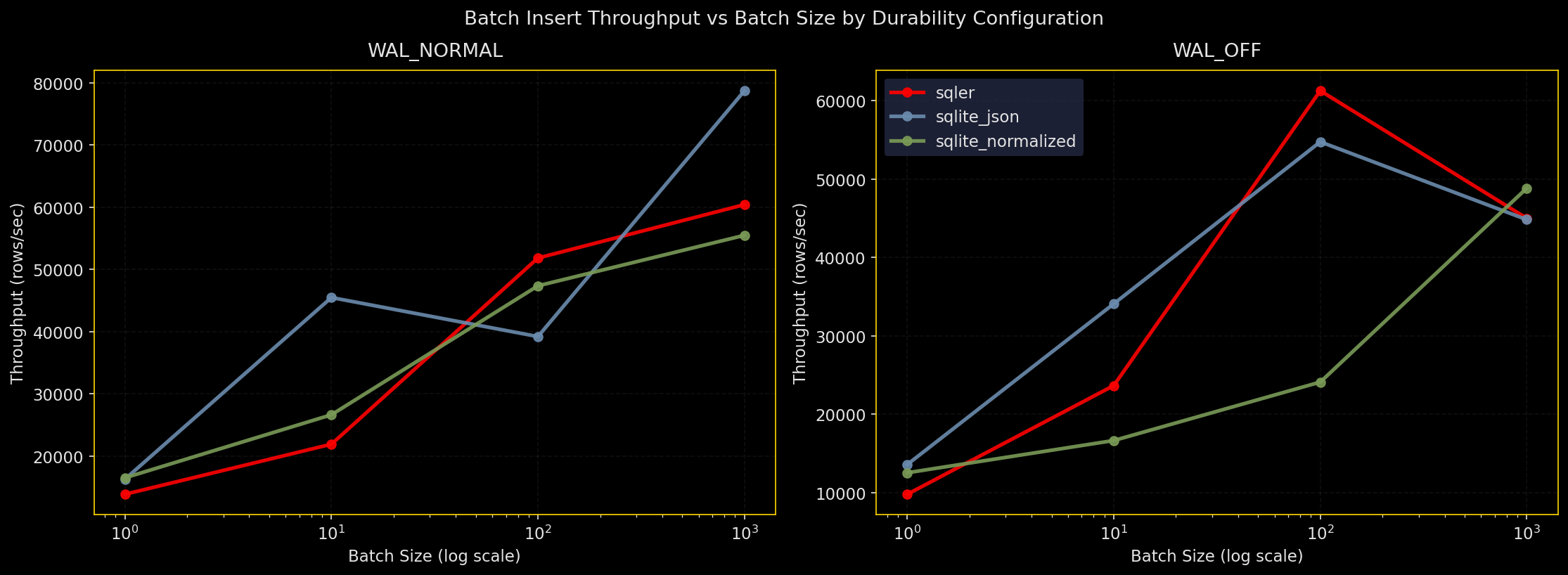

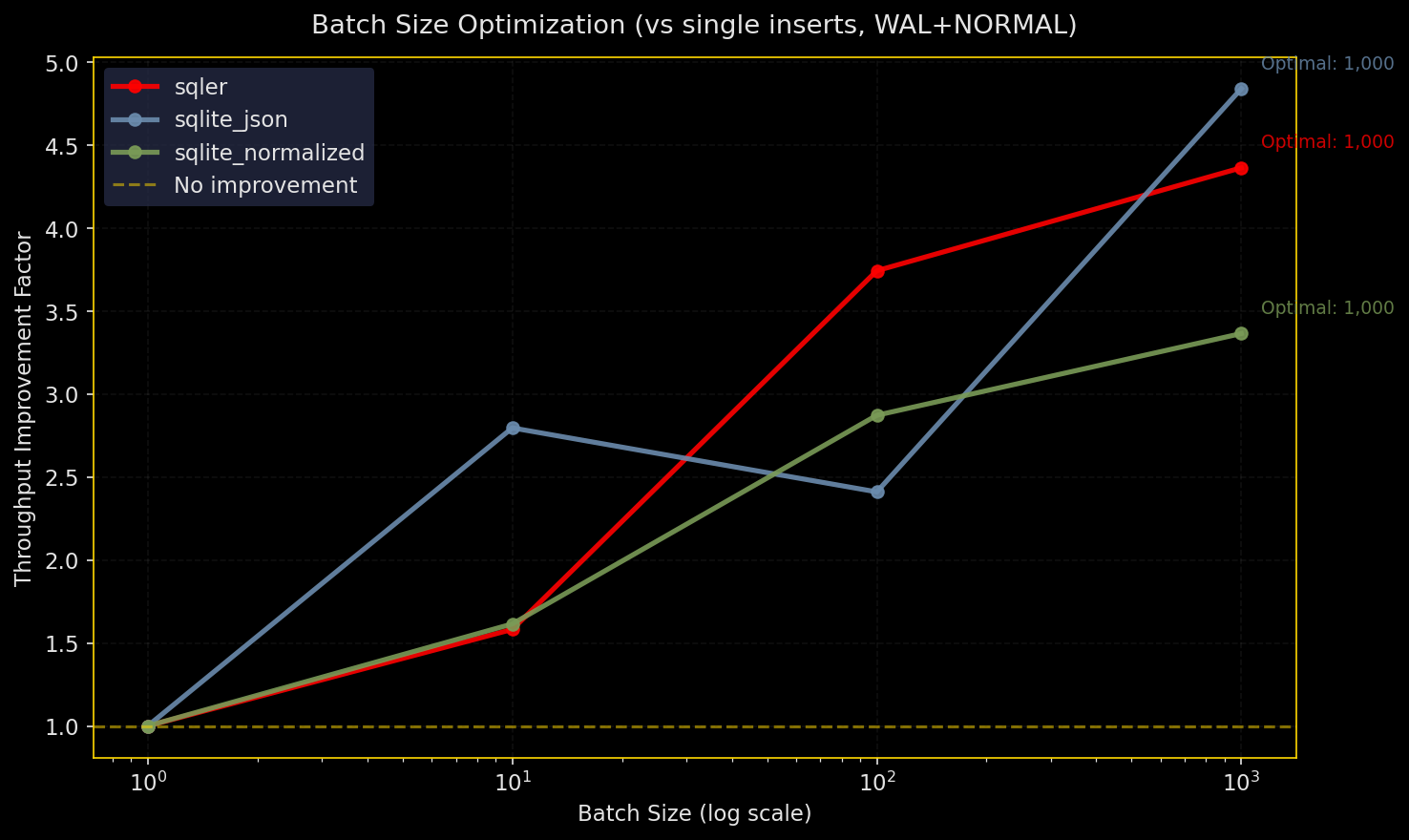
なぜテストするか:挿入は多くのワークロードで支配的。バッチサイズと耐久性設定はスループットに大きく影響する。
何をするか:SQLer の bulk_upsert、生の SQLite JSON(executemany)、正規化カラムで N 行を挿入。耐久性設定は WAL+NORMAL、WAL+FULL、WAL+OFF、DELETE+FULL を試す。3 回実行し、スループットと中央値を報告。
結果:
- 全エンジンとも大きなバッチを好む
- 生の SQLite JSON がやや最高スループットを出すが、SQLer も近く、正規化も競争力あり
synchronous=OFFが最速だが危険、FULLが最も遅いが安全、実務上はWAL+NORMALが現実的な折衷
SQLer の API カバレッジ:bulk_upsert と create_index は公開 API を使用。PRAGMA 設定やテーブルリセットは db.adapter.execute() を使っているが、挿入の本番パスは SQLer の公開 API を通る(プロット/凡例では sqler+sql とマーク)。Production guidance: 大きめのバッチと WAL+NORMAL を使うと、耐久性と実用的なスループットの両方を得やすい。
# throughput_vs_batch_size.png の抜粋
for i, config in enumerate(configs):
ax = axes.flatten()[i]
cd = df[df["config_name"] == config]
for engine in sorted(cd["engine"].unique()):
ed = cd[cd["engine"] == engine]
ax.plot(ed["batch_size"], ed["throughput"],
color=ENGINE_COLORS.get(engine, "#666"), linewidth=2.5, marker="o",
label=engine, alpha=0.9)
ax.set_xscale("log"); ax.set_xlabel("Batch Size (log)")
ax.set_ylabel("Throughput (rows/sec)")
選択的更新:選択率 × 深度
図:
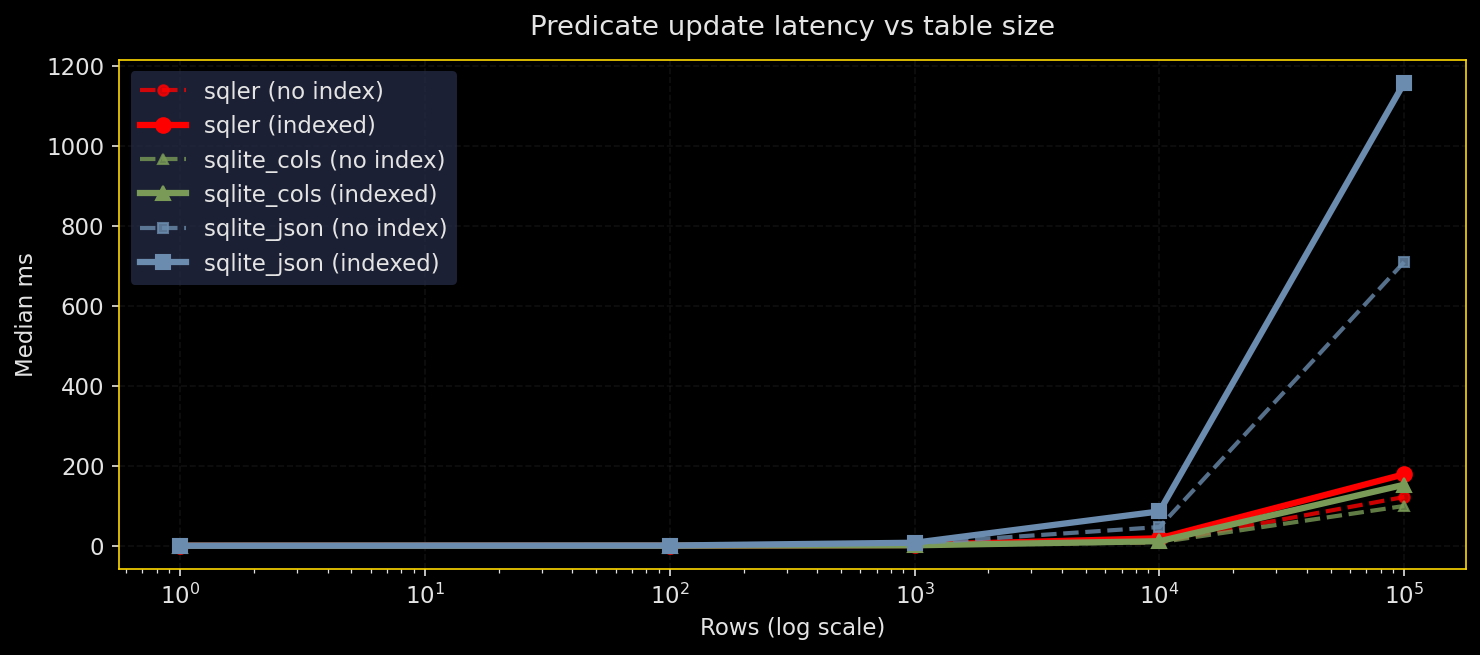
なぜテストするか:更新は JSON ブロブの不利が出やすい。ドキュメント全体を書き換える必要がある更新はコストが高い。
何をするか:json_set() を使ったフィールド更新を、選択率(0.1%〜50%)と更新深度(浅い/深い)で試す。述語フィールドにインデックス有り/無しで比較。対象は SQLer、生の SQLite JSON、正規化カラム。
結果:
- 低選択率の更新は述語インデックスの恩恵を受ける(全エンジンで)
- 大量更新(10〜50%)は正規化スキーマが有利
- 多数の行が変更されるとインデックスの更新コストでインデックス付き更新の方が遅くなることがある
- SQLer は SQLite より少ないバイトを書き換えることはできない。JSON ブロブ書き換えコストは本質的
SQLer の API カバレッジ:更新 API が整備されていないため、ベンチでは db.adapter.execute() による生 SQL を使っている(プロット/凡例では sqler+sql とマーク)。データロードと述語インデックスは公開 API を使用している。Production guidance: 広範な頻繁更新があるなら正規化カラムを優先し、低選択率の更新には述語インデックスを使う。
# latency_vs_selectivity_by_depth.png の抜粋
for i, depth in enumerate(sorted(df["update_depth"].unique())):
ax = axes[i]
dd = df[df["update_depth"] == depth]
for engine in sorted(dd["engine"].unique()):
for indexed in [False, True]:
subset = dd[(dd["engine"] == engine) & (dd["indexed"] == indexed)]
ls = "-" if indexed else "--"
label = f"{engine} ({'indexed' if indexed else 'no index'})"
ax.plot(subset["selectivity"], subset["median_ms"],
color=ENGINE_COLORS.get(engine,"#666"),
linestyle=ls, marker="o", linewidth=2.5, label=label)
配列のメンバーシップ:タグに X が含まれるか
図:
なぜテストするか:“タグに ‘pro’ が含まれる” のような検索は古典的。JSON は書きやすいが、高速にしたければ逆インデックス(補助テーブル)が必要。
何をするか:json_each によるスキャン、補助テーブル(逆インデックス)、および SQLer の現在の挙動(スキャンにマップ)を比較。配列長(3, 10)、選択率(10%、50%)、テーブルサイズ(10K, 100K)を変化させる。
結果:
- 補助テーブル+インデックスが、トイサイズを超えると最速
json_eachスキャンと現在の SQLer の挙動は類似しており、大規模では遅い- 配列メンバーシップが頻繁なら逆インデックスを作るべき
SQLer の API カバレッジ:SQLer は現時点で最適な SQL にコンパイルする一級の “配列 contains” 演算子を持たないため、ベンチは json_each を使った生 SQL を使った(プロット/凡例では sqler+sql とマーク)。配列全体をインデックス化するだけでは効果が薄いのは当然の結果。
Aux table(逆インデックス)
CREATE TABLE user_tags (
user_id INTEGER NOT NULL,
tag TEXT NOT NULL,
PRIMARY KEY (user_id, tag)
);
CREATE INDEX user_tags_tag_idx ON user_tags(tag);
-- トリガー(挿入、更新、削除)が users.data->$.tags から user_tags を同期
補助テーブル(逆インデックス)は値 → ドキュメント ID を対応付けるので、配列の包含チェックが JSON スキャンではなくシンプルなインデックス検索で済むようになる。
# performance_by_array_length.png の抜粋
for i, sel in enumerate(sorted(df["selectivity"].unique())):
ax = axes[i]; sd = df[df["selectivity"] == sel]
for engine in sorted(sd["engine"].unique()):
for indexed in [False, True]:
subset = sd[(sd["engine"]==engine) & (sd["indexed"]==indexed)]
ls = "-" if indexed else "--"
label = f"{engine} ({'indexed' if indexed else 'no index'})"
ax.plot(subset["array_length"], subset["median_ms"],
color=ENGINE_COLORS.get(engine,"#666"),
linestyle=ls, linewidth=2.5, marker="o", label=label)
並行性:書き込み側と読み取り側
図:
なぜテストするか:SQLite は多読・単写のモデル。競合状態で書き込みスループットや読み取りレイテンシはどう変わるか?
何をするか:50K 行を事前ロード。固定期間で N 人のライター(バッチ挿入)と M 人のリーダー(等価検索)を走らせる。書き込みスループットと読み取りレイテンシ(中央値と p95)を記録。対象は SQLer、生の SQLite JSON、正規化カラム。全て WAL+NORMAL。
結果:
- 書き込みスループットは期待通り single-writer の制約で頭打ちになる
- 読み取りレイテンシは負荷下では SQLer が最小に出る傾向(スレッドローカル接続の扱い+WAL の効果のためと推測)
- 読み書きを増やすとスケーリング効率は低下する(奇跡は起きない)
SQLer の API カバレッジ:SQLerDB セットアップ、bulk_upsert、create_index、SQLerQuery(F("field_0") == value) といった公開 API を使っている。PRAGMA やテーブル削除などのセットアップは db.adapter.execute() を使っている(プロット/凡例では sqler+sql とマーク)。Production guidance: SQLite の single-writer モデルを前提に設計し、バッチ化・短いトランザクション・WAL を活用して読み取り時の並列性を高めてください。
# writer_throughput_vs_readers.png の抜粋
for engine in sorted(write_df["engine"].unique()):
ed = write_df[write_df["engine"] == engine]
for nw in sorted(ed["num_writers"].unique()):
subset = ed[ed["num_writers"] == nw]
ax.plot(subset["num_readers"], subset["throughput"],
color=ENGINE_COLORS.get(engine,"#666"), marker="o", linewidth=2.5,
label=f"{engine} ({nw} writer{'s' if nw>1 else ''})", alpha=0.9)
これらのテストは意味があるか?
短く言えば:ある。エンジニアリング判断に値する。
Apples-to-apples:等価フィルタとバッチ挿入はエンジン間のクリーンな比較。
意図した “Oranges”:更新は JSON ブロブ書き換えとスカラ列更新の比較で、完全に同一の作業ではない。だが、それが何をトレードオフしているかを示すには適切な対比。
純粋な SQLer ではない箇所:深い JSON パス、配列のメンバーシップ、更新文は adapter.execute() を使っている。結果が無効になるわけではなく、“純粋な API” ストーリーを完成させるための API ギャップを示している。
足りないもの
スイートを “pure SQLer” にする:
- 深いパス用に
db.create_index(table, path="level_0.level_1.field")を追加 F([...])がF("field")と同様にネストされた JSON パスをコンパイルするようにするQuery.count()とQuery.exists()を追加してlen(q.all())を避ける- 効率的な
json_setにコンパイルするupdate_where()とset()API を公開する
配列メンバーシップの使い勝手:
- 宣言された配列パス用にトリガーで補助テーブル (doc_id, tag_value) を維持するオプトインヘルパーを提供
- 補助テーブルがある場合に利用する
contains()を提供
チャートの磨き: カラーブラインド対応のパレットを主要ラインに使用し、現在の色はアクセントに留め、中央値の周りに p95 バンドを追加することを検討
結果は SQLer が SQLite の制約内で予測可能に振る舞うことを示す。式インデックスは JSON クエリを高速にし、バルク操作は期待通りの挙動を示し、並行性は single-writer の限界に当たる。運用に十分だが、API の改善余地あり。
備考:凡例で「sqler+sql」と表示されている項目は、セットアップやデータ投入に SQLer を用い、ホットなクエリは db.adapter.execute() 経由の生 SQL で実行したことを示します。