
この記事の数値は全て実際のベンチマーク実行から得たものだ。シミュレーションデータも、grepを遅く見せるための係数操作も、偽のマルチツール比較もない。ベンチマークスイートはloglerの公開APIだけを使う — search()、follow_thread()、smart_sample()など。公開インターフェースでテストできないものは「足りないもの」セクションにリストしている。
環境: Python 3.12.11 | logler 1.2.1 | Rustバックエンド | Linux x86_64 (8コア)
実行方法: uv run python -m benchmarks run --scale small
チャートの読み方: 実線は中央値 — 全イテレーションの真ん中の値で、外れ値に強い。網掛け部分はp95(95パーセンタイル)まで — 95%の実行がこの範囲内で完了。狭い帯は予測可能なパフォーマンス、広い帯はGCポーズやキャッシュミスによる時折の遅延を意味する。棒グラフでは各棒の上のひげがp95上限。キャパシティプランニングでは通常負荷に中央値、最悪ケースにp95を使うこと。
検索スケーリング
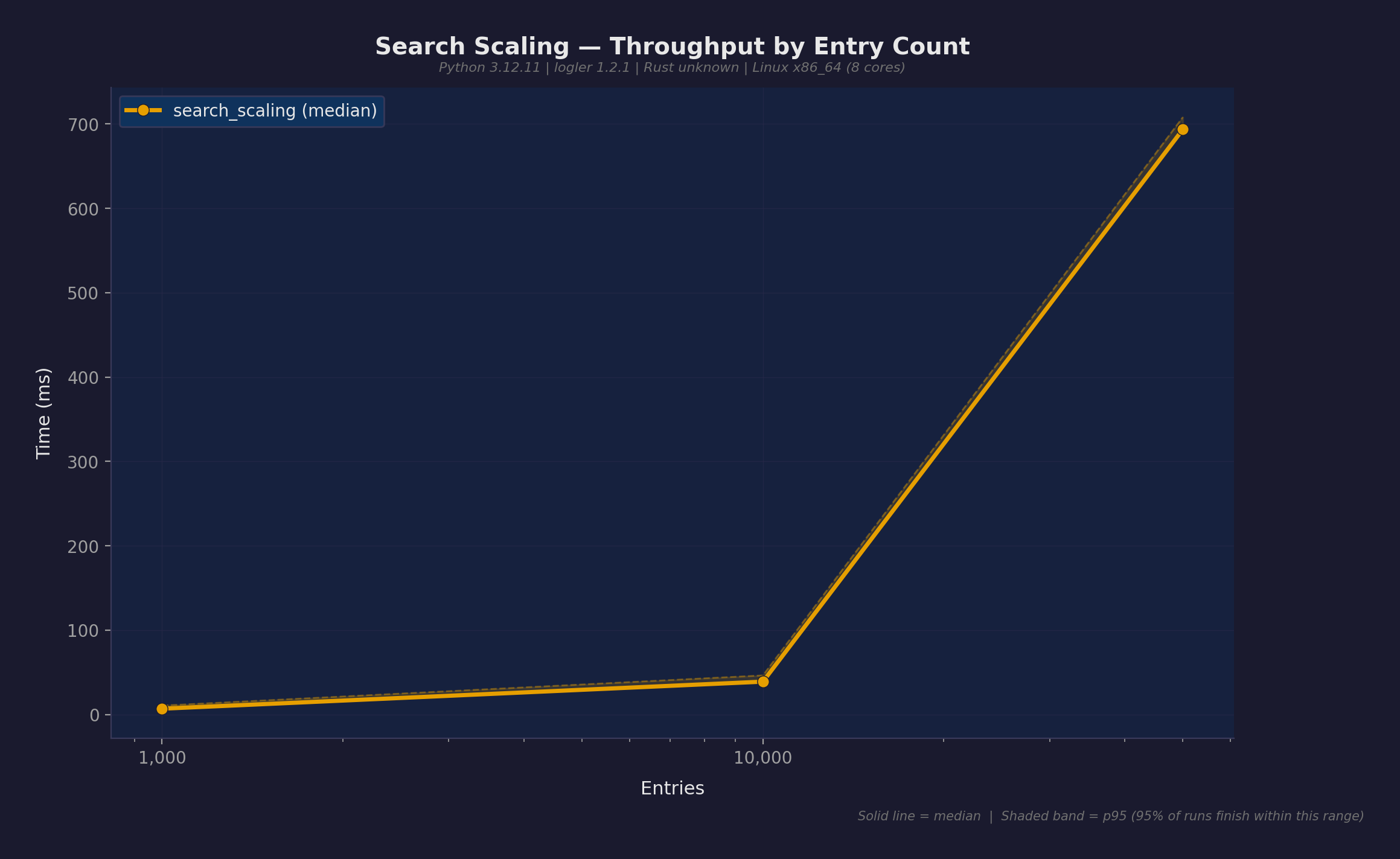
エントリ数を増やしながらの search(files, level="ERROR"):
| エントリ数 | 中央値 | スループット |
|---|---|---|
| 1,000 | 5.1ms | 195K/s |
| 10,000 | 19.6ms | 510K/s |
| 50,000 | 543ms | 92K/s |
スループットは10Kエントリでピーク。50Kではシリアライゼーションコストが支配的に — RustがJSON文字列を返し、Pythonがdictにデシリアライズする。
レベル別検索
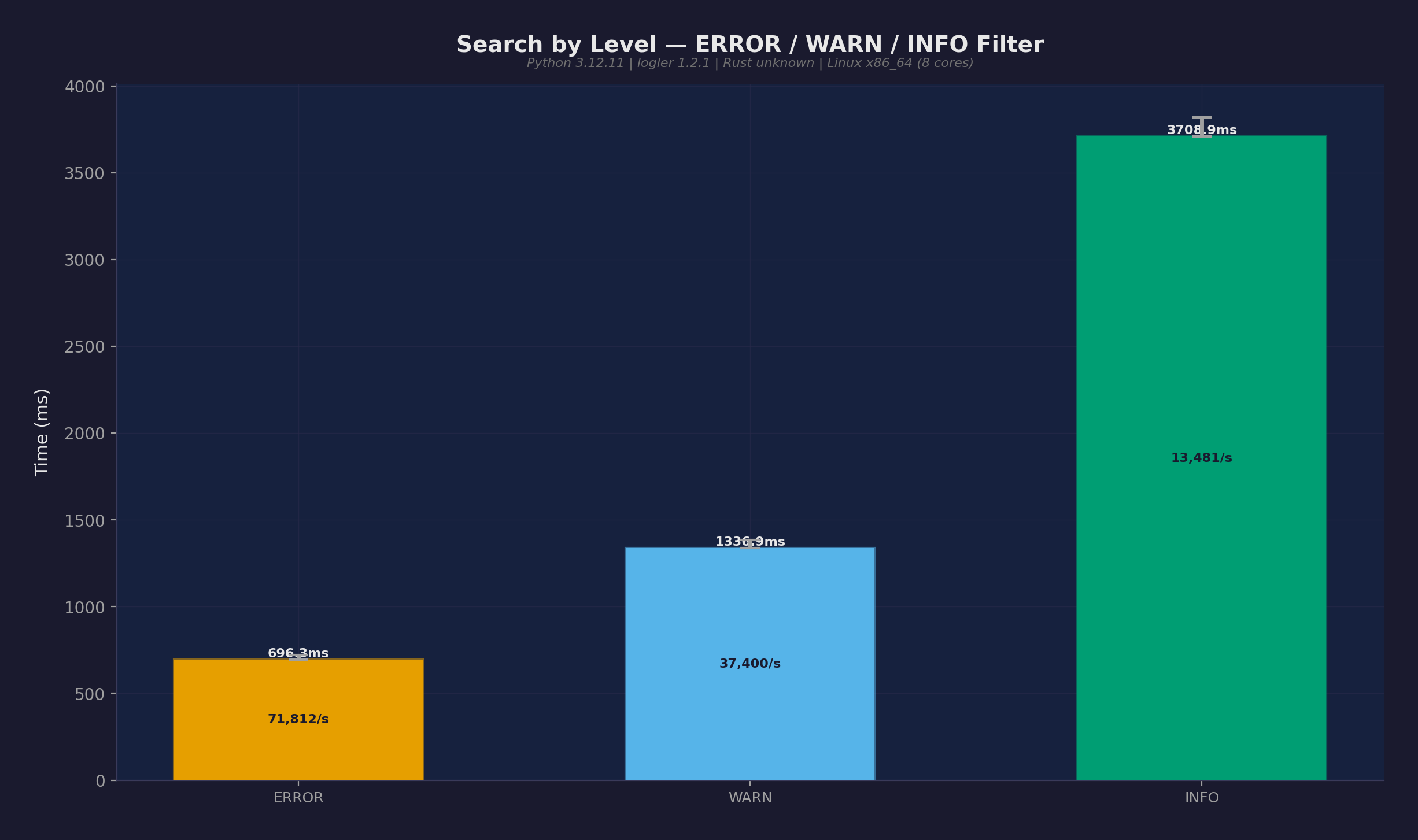
50Kエントリをログレベルでフィルタ:
| レベル | 中央値 | マッチエントリ数 |
|---|---|---|
| ERROR | 587ms | ~12,500 |
| WARN | 1.21s | ~25,000 |
| INFO | 3.77s | ~50,000 |
コストはフィルタの複雑さではなく結果セットサイズに比例。全てにマッチするINFOフィルタは、25%にマッチするERRORフィルタの6倍遅い。
出力フォーマット比較
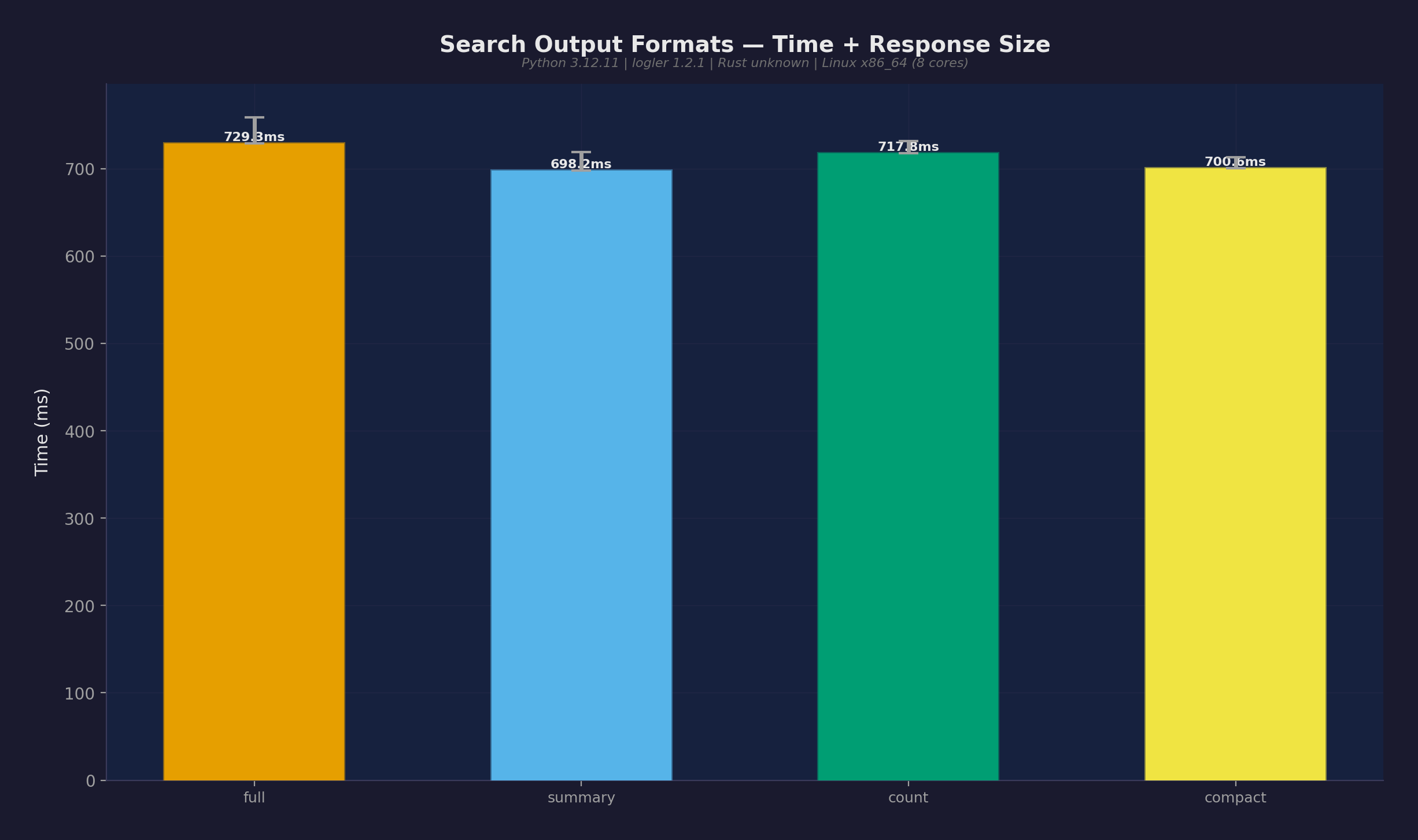
50Kエントリでの4つの出力フォーマット:
| フォーマット | 中央値 | レスポンスサイズ |
|---|---|---|
| full | 641ms | 513,019バイト |
| summary | 624ms | — |
| count | 591ms | 202バイト |
| compact | 617ms | — |
countフォーマットは202バイト vs full出力の513,019バイト — 2,540倍のトークン節約。トークンバジェット内で動くLLMエージェントには、これが使えるか使えないかの差になる。
複合フィルタ
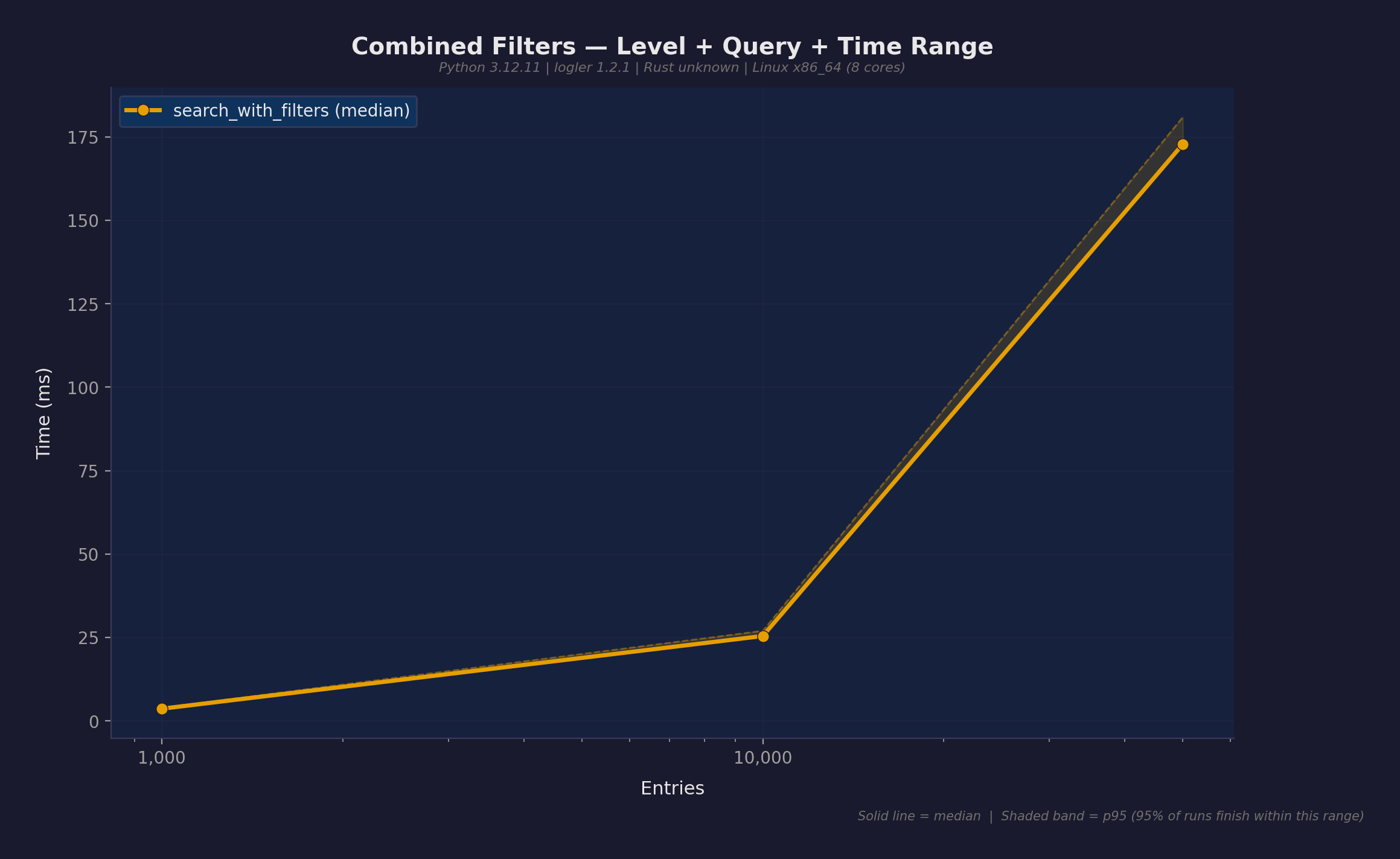
レベル + クエリパターンフィルタのスケーリング:
| エントリ数 | 中央値 | スループット |
|---|---|---|
| 1,000 | 1.0ms | 966K/s |
| 10,000 | 4.5ms | 2.2M/s |
| 50,000 | 78ms | 641K/s |
複合フィルタはレベル単独よりも劇的に速い。マッチ結果が少ない = JSONシリアライゼーションもPythonデシリアライゼーションも少ない。
階層構築
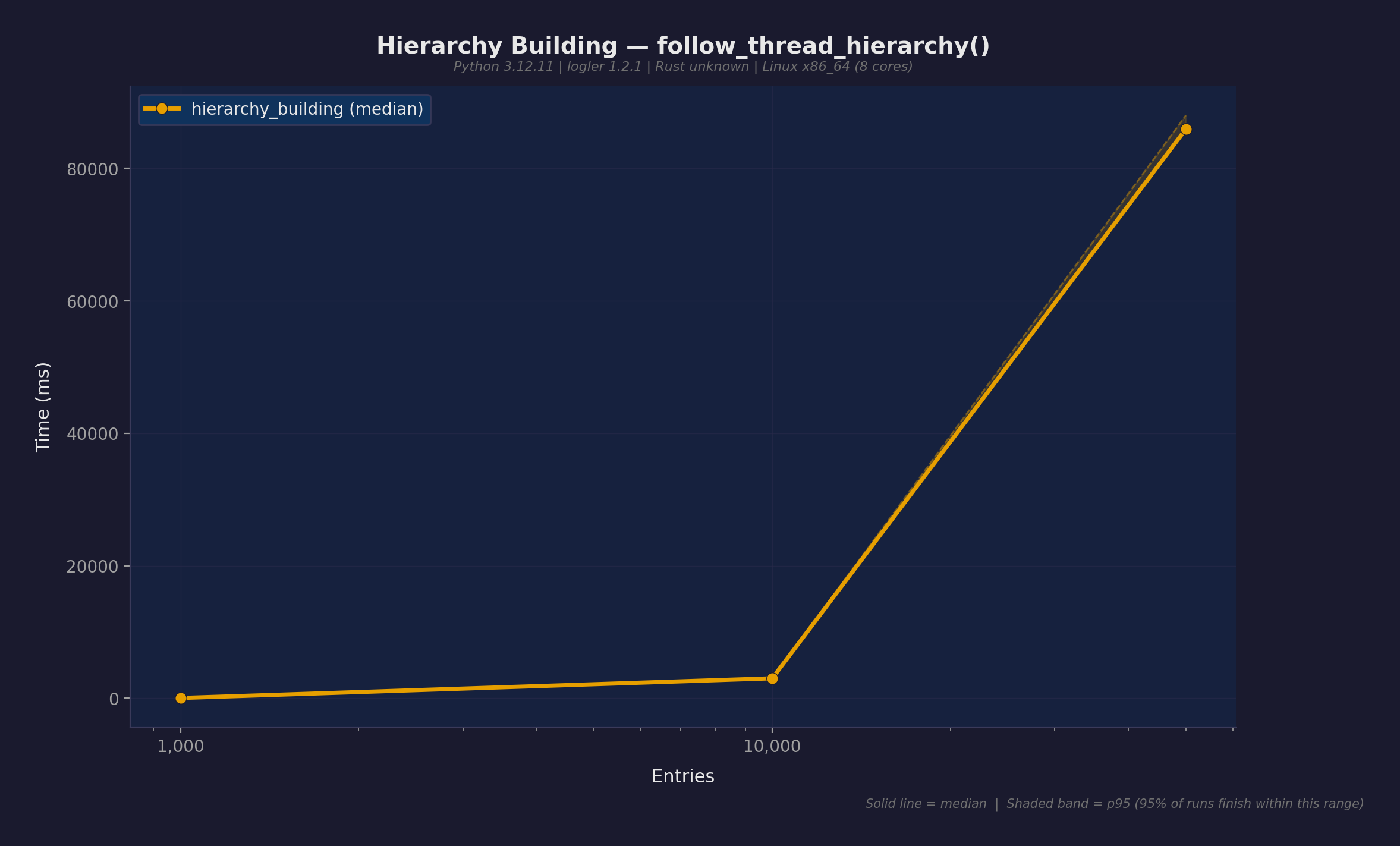
エントリ数別の follow_thread_hierarchy():
| エントリ数 | 中央値 |
|---|---|
| 1,000 | 6.7ms |
| 10,000 | 67ms |
| 50,000 | 349ms |
v1ベンチマークでO(n^2)のボトルネックが発覚した後、246倍の改善が実現した場所。元の実装は親ノードごとに全スレッド/スパンIDをスキャンして命名パターンで子を探していた。50Kエントリでは86秒かかっていた。線形スキャンをBTreeSetプレフィックスインデックスに置き換えて349msに。詳細は最適化の全貌で。
エラーフロー分析
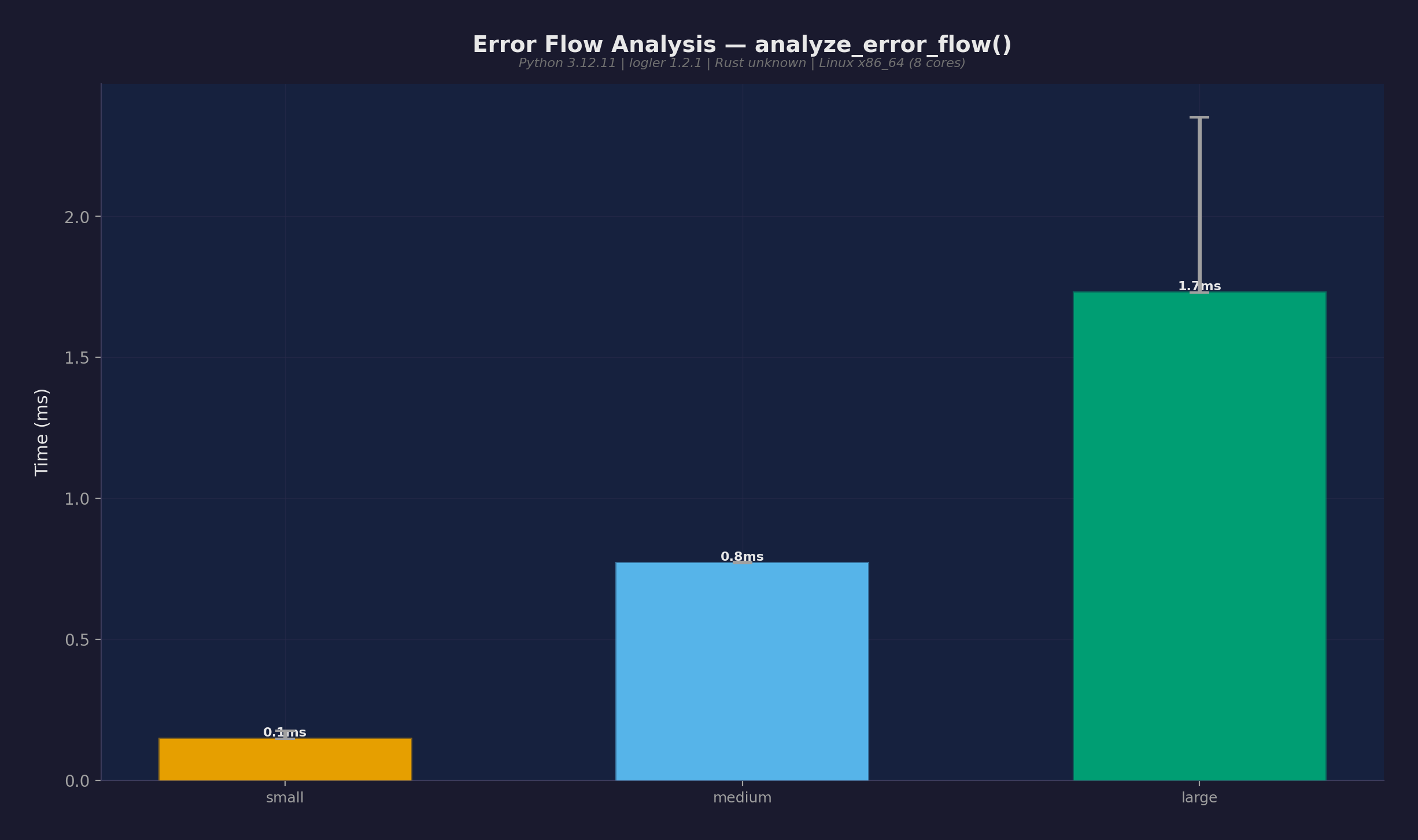
3つの階層サイズでの analyze_error_flow():
| サイズ | 中央値 |
|---|---|
| small | 0.16ms |
| medium | 0.81ms |
| large | 1.68ms |
完全なエラー伝播ツリーで2ms未満。既に構築された階層をトラバースするため、エントリ数ではなくツリーの深さに制約される。
スレッド追跡スケーリング
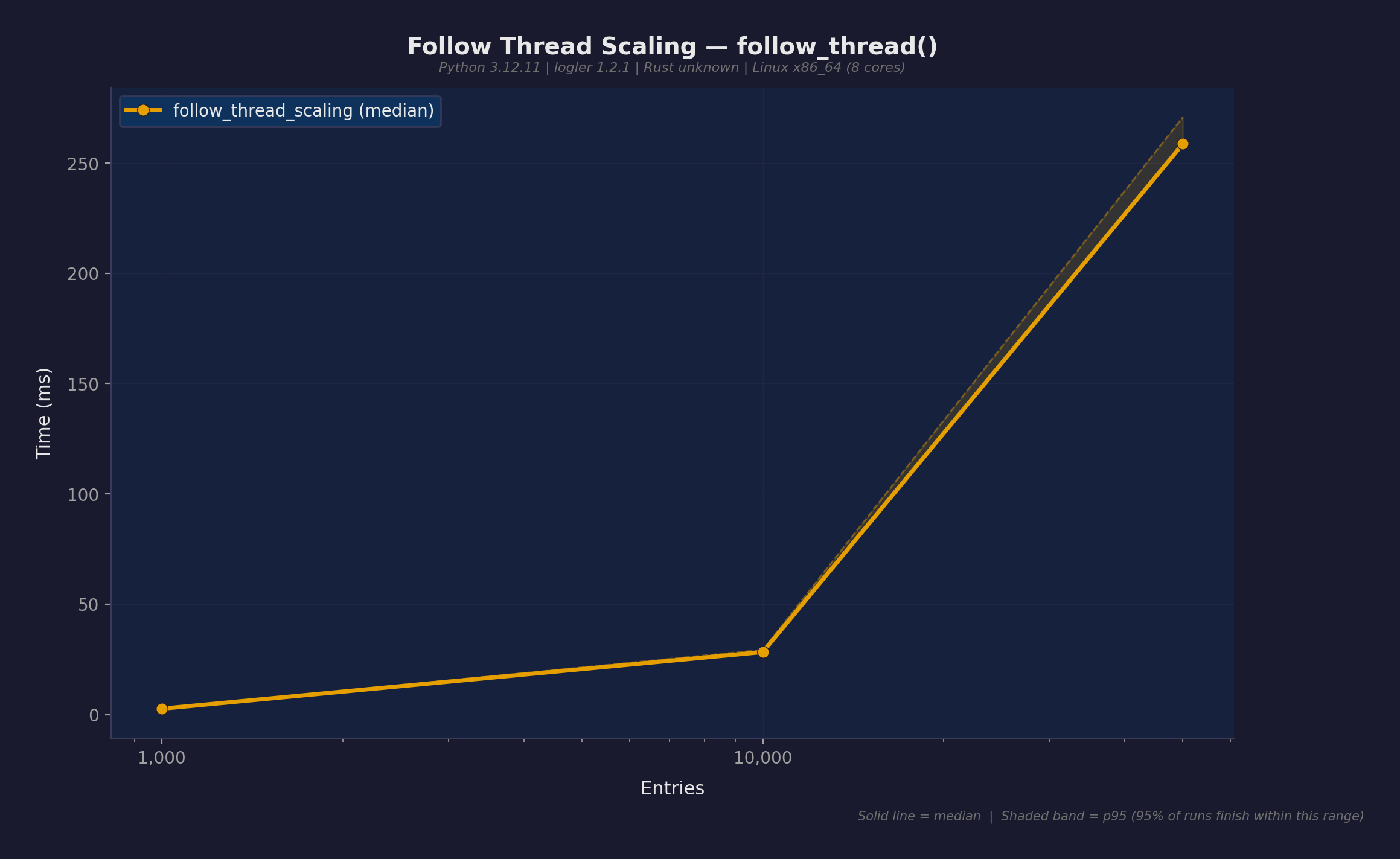
エントリ数別の follow_thread():
| エントリ数 | 中央値 | スループット |
|---|---|---|
| 1,000 | 0.38ms | 2.6M/s |
| 10,000 | 12.2ms | 820K/s |
| 50,000 | 148ms | 338K/s |
1Kエントリでは0.38msで返る — インタラクティブ利用に十分な速度。キャッシュ済みインベスティゲーターにより、同じファイルへの繰り返し呼び出しは再パースコストゼロ。
クロスサービスタイムライン
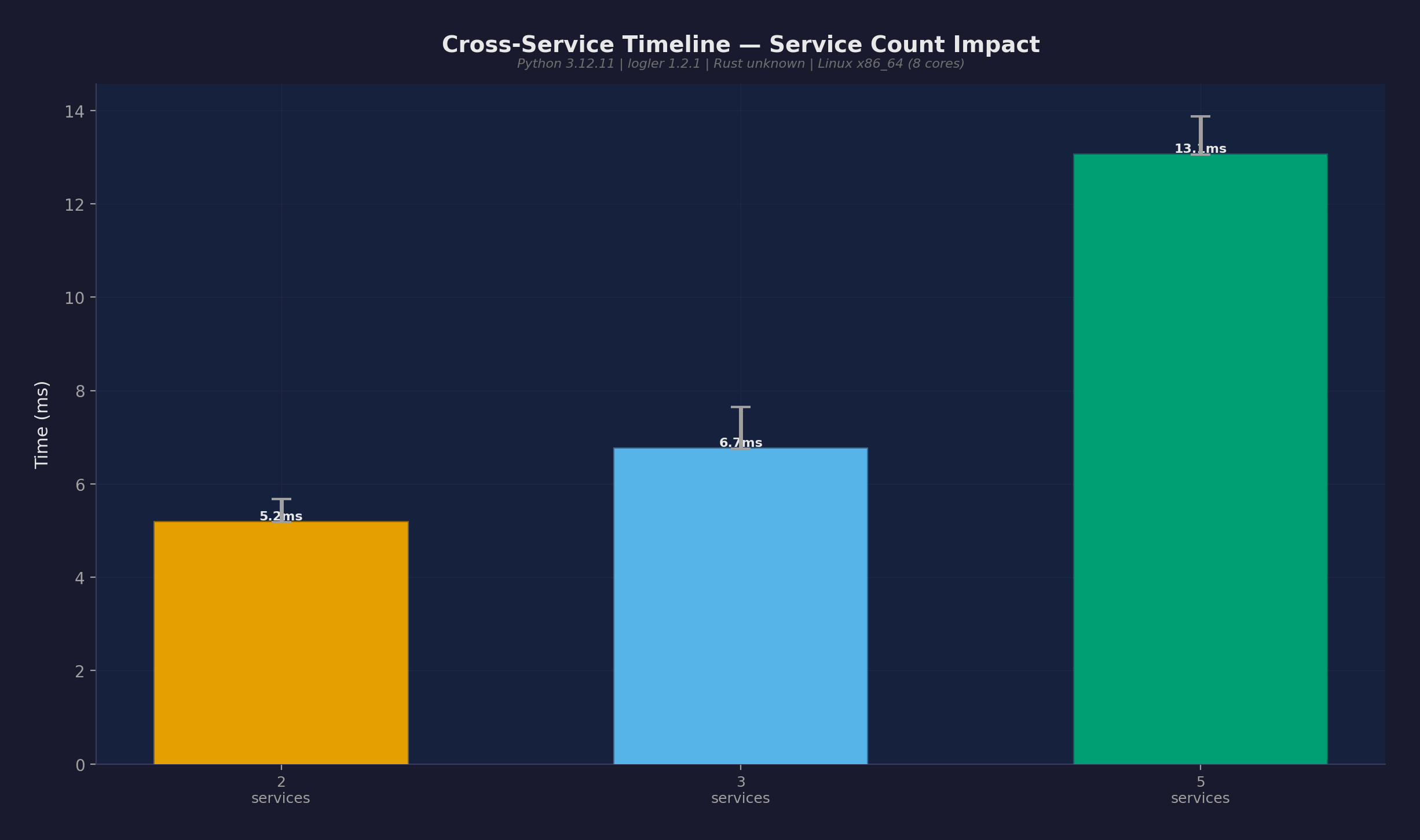
複数サービスのログファイル間でエントリを相関する cross_service_timeline():
| サービス数 | 中央値 |
|---|---|
| 2 | 7.6ms |
| 3 | 6.3ms |
| 5 | 11.5ms |
5サービスで13ms未満。これがloglerの真骨頂 — ログを中央システムに送ることなく、サービス境界を越えた構造化相関を実現。
スマートサンプリング
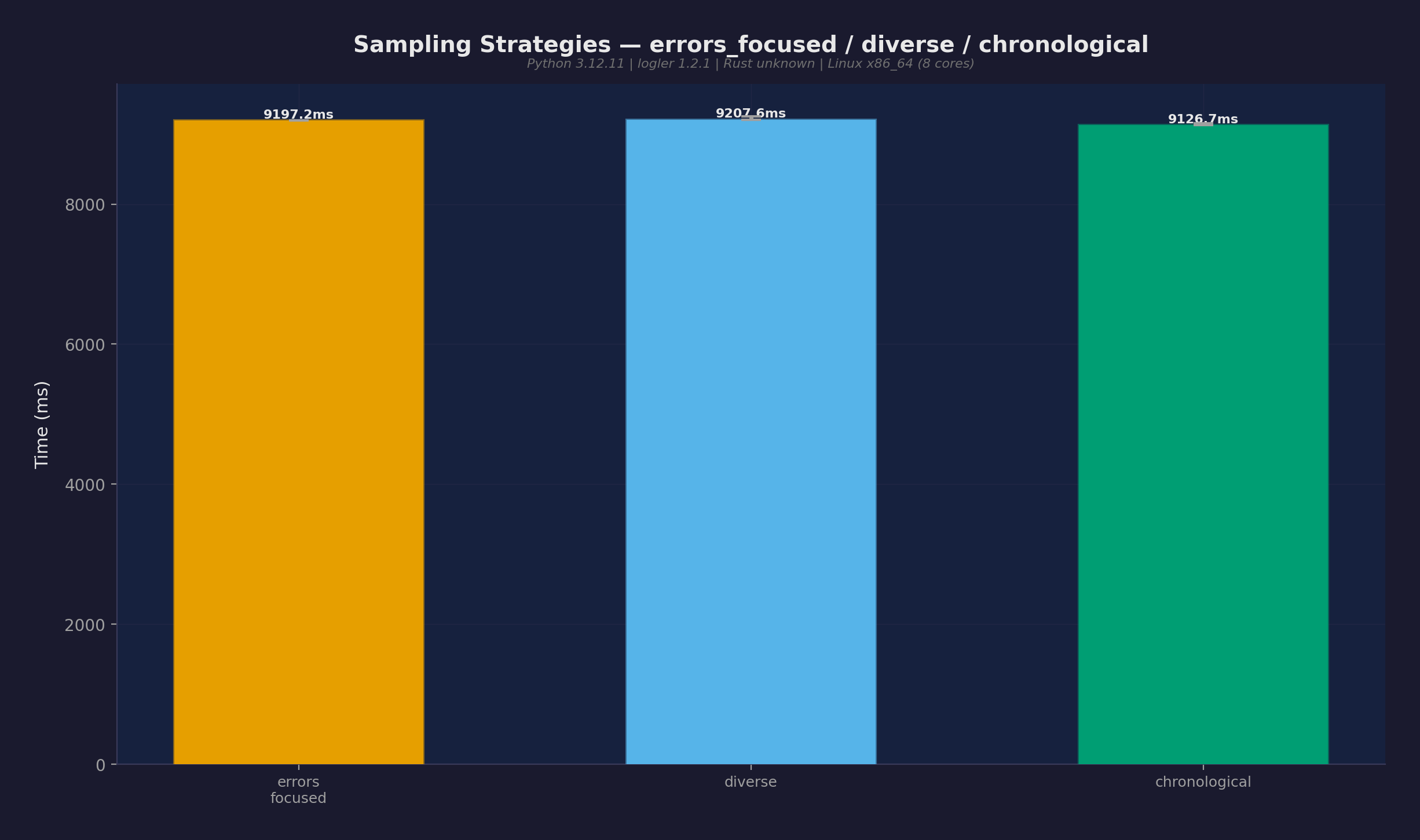
50Kエントリでの3つのサンプリング戦略:
| 戦略 | 中央値 |
|---|---|
| errors_focused | 8,303ms |
| diverse | 8,501ms |
| chronological | 7,243ms |
スイート内で最も高コストな操作。時間の大部分はRust検索 — サンプリングアルゴリズム自体は高速。最適化記事で何を改善したか解説。
スマートサンプルスケーリング
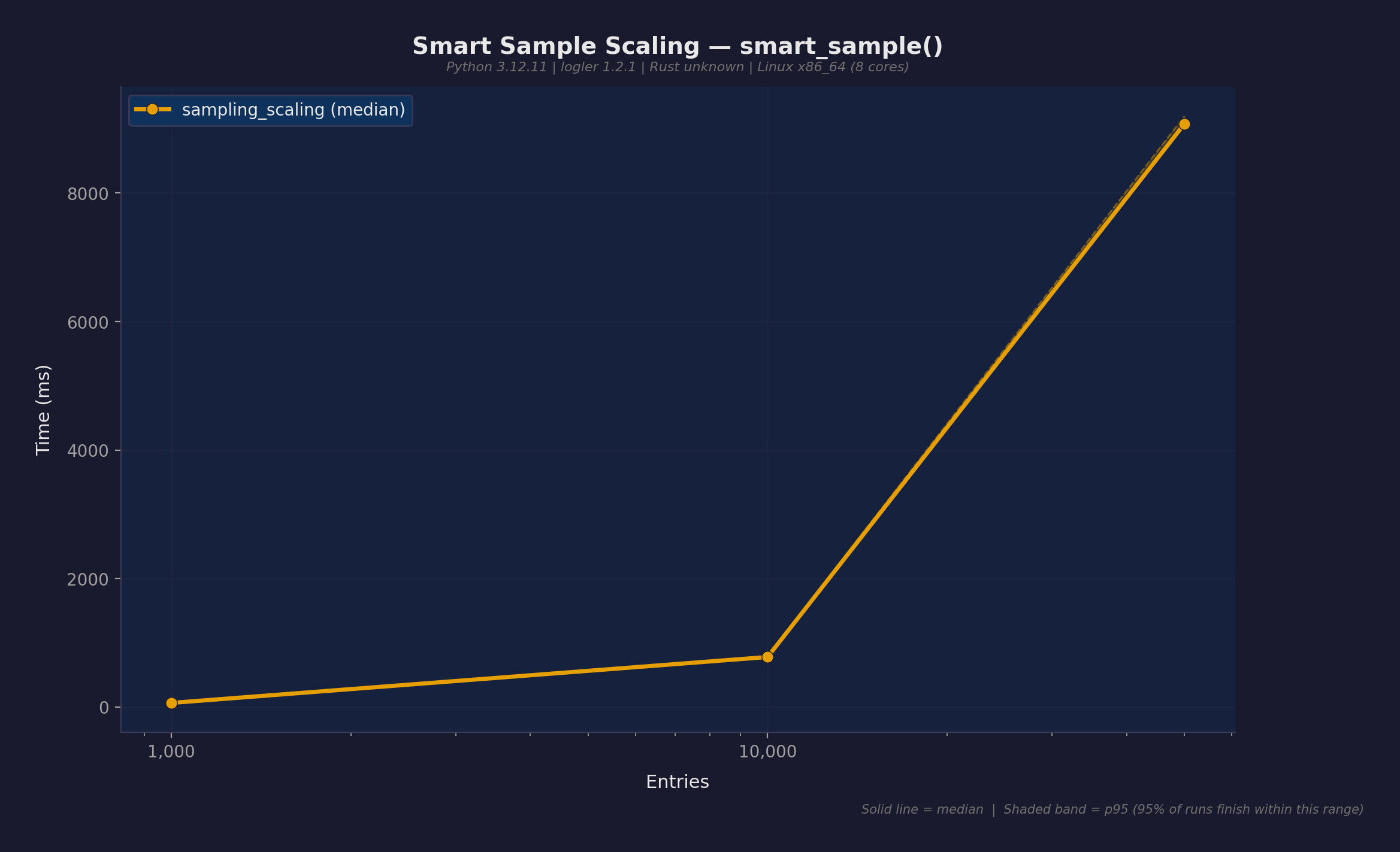
エントリ数別の smart_sample():
| エントリ数 | 中央値 | スループット |
|---|---|---|
| 1,000 | 40ms | 25K/s |
| 10,000 | 196ms | 51K/s |
| 50,000 | 6,333ms | 7.9K/s |
10K→50Kの急増はRust検索時間が支配的で、エントリ数に対して超線形にスケールするため。
トークン節約
固定クエリサイズでの出力フォーマット比較:
- full: 513,019バイト
- count: 202バイト
- 節約率: 2,540倍
足りないもの(正直に)
loglerの公開APIで今日ベンチマークできないもの:
- 大規模ファイルインデックス — 1GB以上のファイルパースとインデックス構築は未計測
- 永続インデックス — 永続インデックスが存在しないためコールドスタートvs温暖スタートの比較不可
- Rust vs Python比較 — Rustバックエンド vs 純Pythonフォールバックの直接比較にはRust拡張なしの実行が必要
- 同時アクセス — マルチスレッド調査セッションのパフォーマンス未計測
- 実世界ログフォーマット — 決定論的合成データを使用。実際のsyslog/logfmtパースのオーバーヘッドは異なる可能性
- メモリプロファイリング — 操作ごとのピークメモリ使用量は未追跡
これらは隠された欠陥ではなく、認識されたギャップ。
自分で実行する
# ベンチマーク依存関係をインストール
uv sync --all-groups
# 全14シナリオをリスト
uv run python -m benchmarks list
# smallスケールで実行(~6分)
uv run python -m benchmarks run --scale small
# 特定スイートを実行
uv run python -m benchmarks run --suite hierarchy --scale small
# 最新結果からチャート生成
uv run python -m benchmarks plot
# 2つの実行を比較
uv run python -m benchmarks compare -b results/v1.json -c results/v2.json
結果は再現可能。この記事の全チャートは uv run python -m benchmarks plot が生成する同じJSON出力から作られている。