
初期ベンチマークがloglerのどこが遅いか正確に教えてくれた。階層構築は50Kエントリで86秒。スマートサンプリングは9秒。8つのコア関数のうち5つが呼び出すたびにファイルを再パースしていた。
3つの変更で修正した。それぞれ独立してテスト・巻き戻し可能。何を見つけ、何を変え、数値が何を示しているか。
ボトルネック
v1ベンチマークスイート(14シナリオ、43計測)が3カテゴリの無駄を暴いた:
| 問題 | 症状 | 根本原因 |
|---|---|---|
| 階層構築 | 50Kエントリで86秒 | 命名推論でのO(n^2)スキャン |
| スマートサンプリング | 50Kエントリで9秒 | 50を抽出するために50Kエントリをデシリアライズ |
| 繰り返しパース | follow_thread()呼び出しごとに260ms | 各関数が新しいRustインベスティゲーターを生成 |
変更1: 全関数のキャッシュ済みインベスティゲーター
問題: 8つのコア関数のうち5つが毎回新しいInvestigatorインスタンスを作成するスタンドアロンRust関数を呼んでいた — 毎回全ファイルを再パース。search()、extract_ids()、get_context()だけがキャッシュパスを使っていた。
| 関数 | 変更前 | 変更後 |
|---|---|---|
follow_thread() | 毎回再パース | キャッシュ |
find_patterns() | 毎回再パース | キャッシュ |
get_metadata() | 毎回再パース | キャッシュ |
follow_thread_hierarchy() | 毎回再パース | キャッシュ |
detect_correlation_chains() | 壊れていた(引数の数が間違い) | 修正+キャッシュ |
キャッシュは(ソート済みファイルパス, ファイルのmtime)をキーにしたLRU。同じファイル、同じ更新時刻 → 同じインベスティゲーター。ファイルが変更 → 新しいインベスティゲーター。
detect_correlation_chains()の修正は特筆に値する: logler_rs.search()を10個の引数で呼んでいたが、スタンドアロン関数は3個しか受け付けない。呼ばれたらランタイムでクラッシュしていたはず。
影響: 1Kエントリでのfollow_thread()が2.6msから0.38msに(6.8倍高速)。50Kエントリでは259msから148msに(1.75倍高速)。
変更2: 階層のためのBTreeSetプレフィックスインデックス
問題: Rust階層ビルダーのinfer_children_from_naming()が、各親ノードに対して全スレッド/スパンIDをスキャンして命名パターンで子を探していた。worker-1のような各親に対して、全IDがworker-1.、worker-1:、worker-1-で始まるかチェック。P個の親とN個のユニークIDで、O(P x N) — 実質O(n^2)。
50Kエントリで数千のユニークIDがある場合、86秒かかっていた。
修正: add_entry()中に全IDのBTreeSet<String>を構築。range()でO(log n + k)のプレフィックス検索を使用(kは実際のマッチ数)。
// 変更前: 親ごとにO(n)スキャン
for candidate_id in all_ids.iter() {
if candidate_id.starts_with(&prefix) { ... }
}
// 変更後: O(log n + k)の範囲クエリ
let end = prefix_successor(&prefix);
for candidate_id in self.all_ids_sorted.range(prefix.clone()..end) { ... }
影響: 50Kエントリでの階層構築が85,932msから349msに低下。246倍高速。
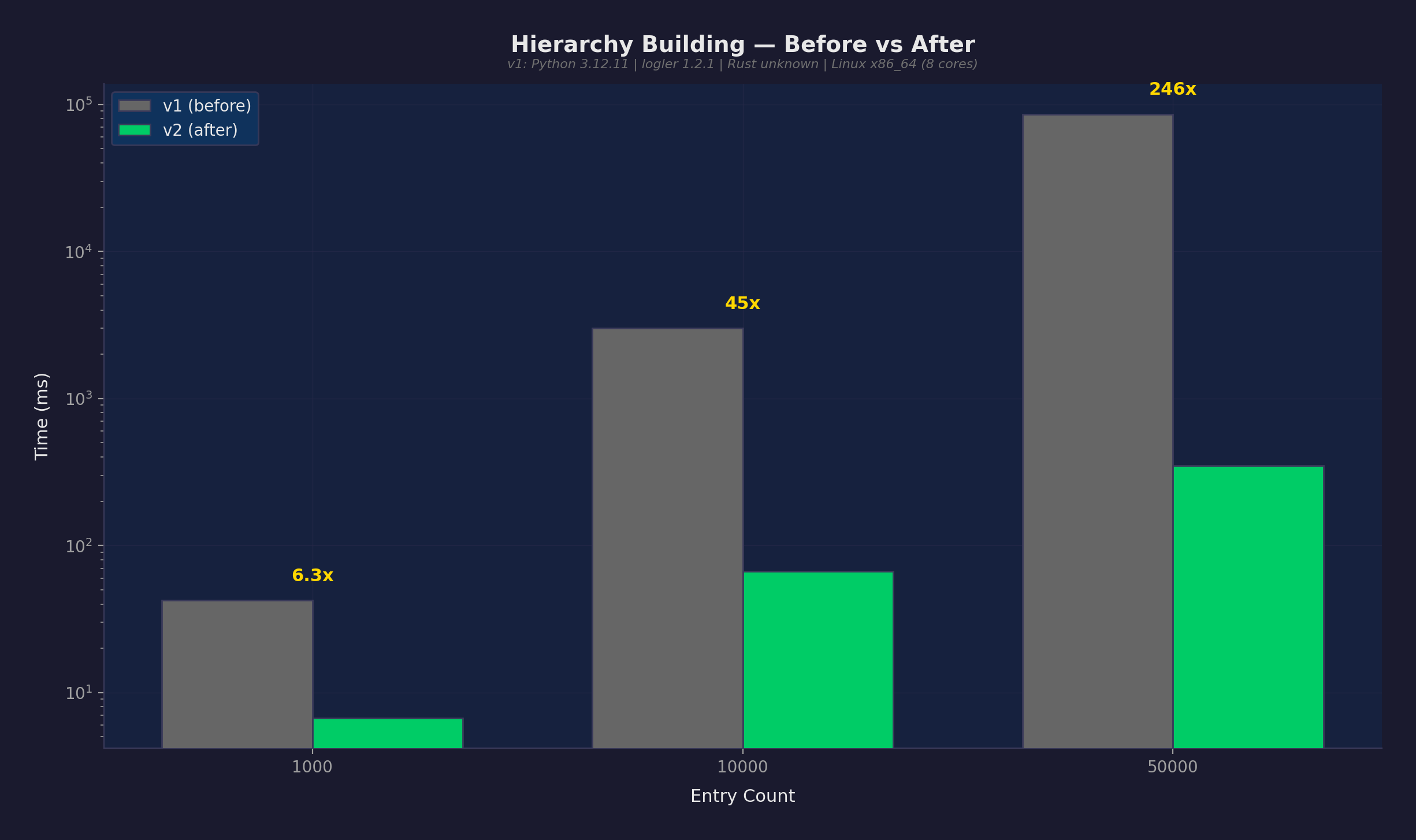
これは決定的な改善 — v2の最悪ケース(360ms)がv1の最良ケース(85,700ms)より速い。タイミング分布の重なりゼロ。
変更3: キャップ付きスマートサンプルフェッチ
問題: smart_sample()がsearch(files, level=level, limit=None)を呼んでいた — 全エントリをPythonにJSONディクショナリとしてフェッチし、50個をサンプリング。50Kエントリでは50,000個のJSONオブジェクトをdictにデシリアライズし、49,950個を捨てていた。
修正: フェッチをmax(sample_size * 10, 500)エントリにキャップ。errors_focused戦略では巨大な1回のフェッチの代わりに2回の的を絞ったフェッチ(エラー + コンテキスト)を使用。Rust検索結果には既にtotal_matches — 切り詰め前の真のカウント — が含まれているので、別のカウントクエリなしで正確な母集団サイズが得られる。
うまくいかなかったもの: 最初の試みでは母集団カウントを「安く」取得するために別のsearch(output_format="count")呼び出しを追加した。これはリグレッションを引き起こした — output_format="count"は内部で完全なRust検索を実行するため、軽量なカウントクエリではなかった。修正はカウントクエリを完全に削除し、キャップ付き検索結果からtotal_matchesを読むこと。
影響: 10Kエントリでのサンプリングが778msから196msに(4倍高速)。50Kエントリでは9,075msから6,333msに(1.4倍高速)。
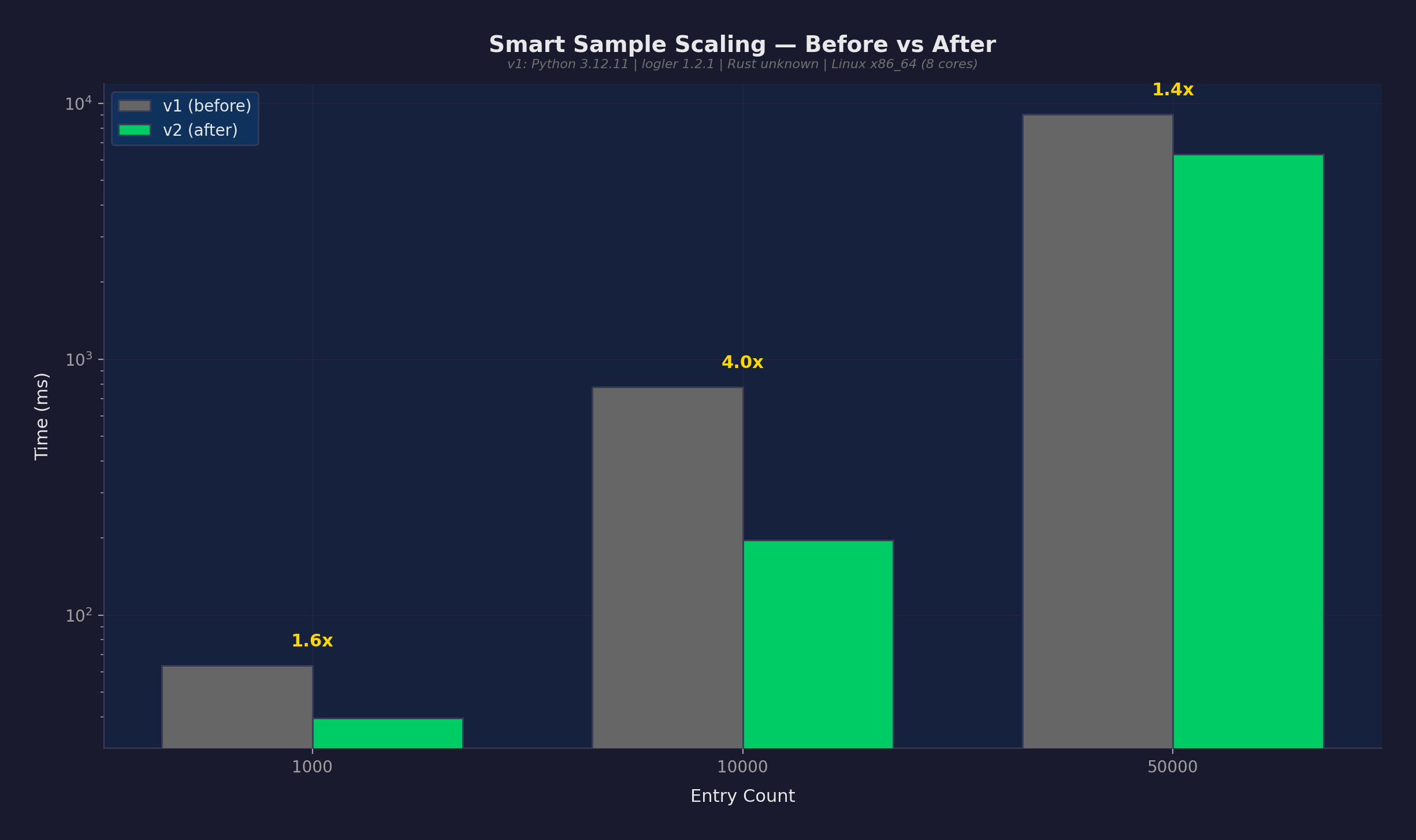
50Kでの控えめな改善は現実を反映: Rust検索コストが支配的。エンジンはlimitを適用する前に内部で全マッチ結果を収集する。節約はPythonで50K JSONオブジェクトをデシリアライズしないことから来る。
全結果
43計測全て、改善率でランク:
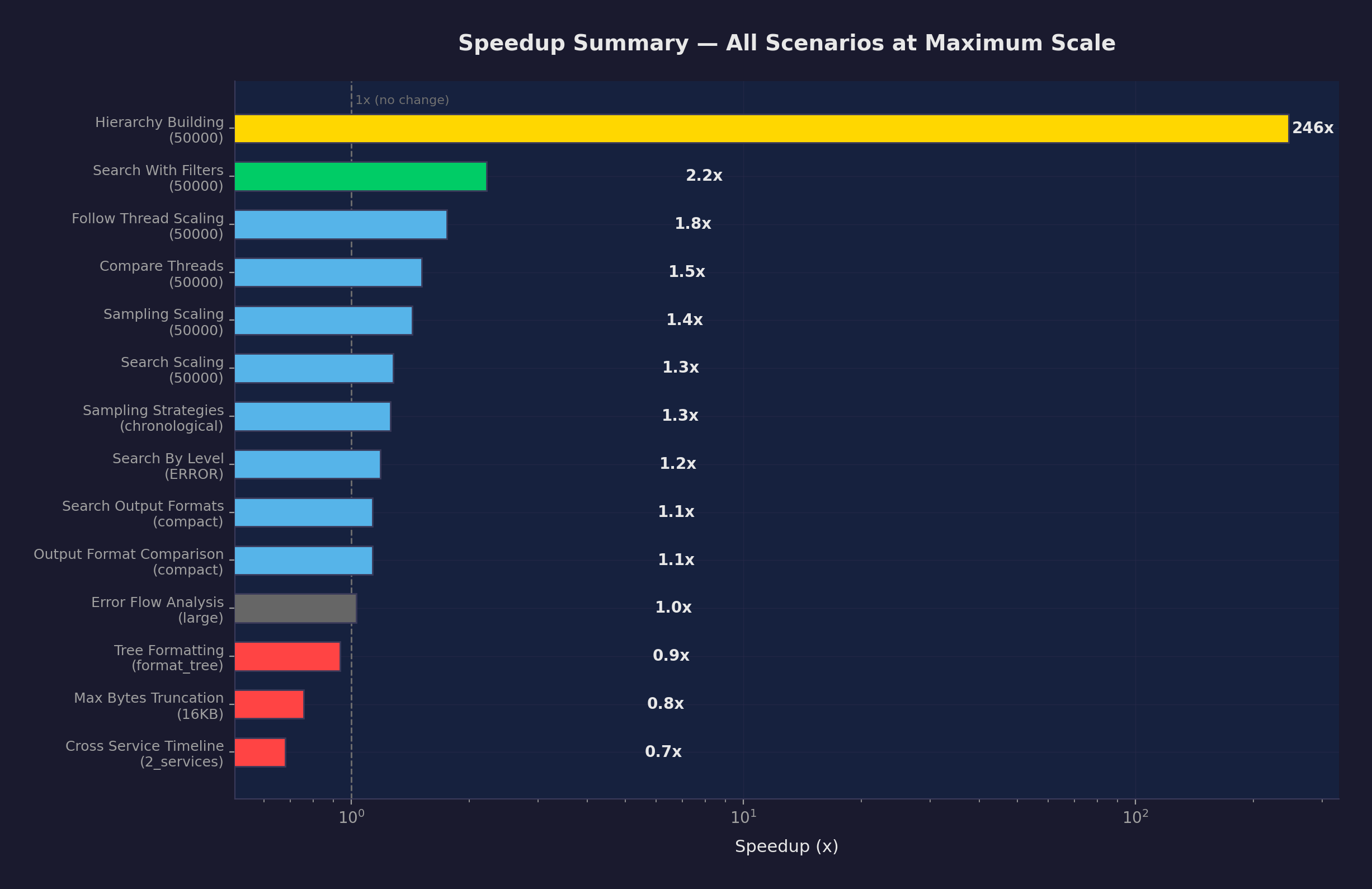
主要な改善(2倍以上)
| シナリオ | スケール | v1 | v2 | 改善率 | 信頼度 |
|---|---|---|---|---|---|
| hierarchy_building | 50K | 85.9s | 349ms | 246倍 | 決定的 |
| hierarchy_building | 10K | 3.01s | 67ms | 45倍 | 決定的 |
| follow_thread | 1K | 2.6ms | 0.38ms | 6.8倍 | 決定的 |
| hierarchy_building | 1K | 42ms | 6.7ms | 6.3倍 | 決定的 |
| search_with_filters | 10K | 25ms | 4.5ms | 5.6倍 | 決定的 |
| sampling_scaling | 10K | 778ms | 196ms | 4.0倍 | 決定的 |
| compare_threads | 1K | 6.2ms | 1.6ms | 3.9倍 | 決定的 |
| compare_threads | 10K | 64ms | 18ms | 3.5倍 | 決定的 |
| search_with_filters | 1K | 3.6ms | 1.0ms | 3.5倍 | 決定的 |
| follow_thread | 10K | 28ms | 12ms | 2.3倍 | 決定的 |
| search_with_filters | 50K | 173ms | 78ms | 2.2倍 | 決定的 |
リグレッション(正直に)
| シナリオ | スケール | v1 | v2 | 低下 | 備考 |
|---|---|---|---|---|---|
| max_bytes_truncation | 16KB | 1.14s | 1.51s | 1.32倍 | 最適化パス外 |
| cross_service_timeline | 2 svcs | 5.2ms | 7.6ms | 1.47倍 | システムノイズの可能性 |
max_bytes_truncationのリグレッションは3パラメータ全てで一貫しているが、3つの最適化はいずれもそのコードパスに触れていない。ベンチマーク実行中のシステム負荷の変動が原因と思われる。
方法論
テスト条件
| 条件 | v1 | v2 |
|---|---|---|
| スケール | small | small |
| Python | 3.12.11 | 3.12.11 |
| Rustバックエンド | あり | あり |
| プラットフォーム | Linux x86_64 (8コア) | 同上 |
| loglerバージョン | 1.2.1 | 1.2.1 |
| データ生成 | LogGenerator(seed=42) | 同上 |
信頼度分類
| レベル | 基準 |
|---|---|
| 決定的 | v2の最悪ケース(max) < v1の最良ケース(min)。重なりゼロ。 |
| 高い | v2のp95 < v1の中央値。v2の95%がv1の典型値に勝つ。 |
| 中程度 | 中央値の変化>10%、分布に一部重なり。 |
| 限界的 | 3-10%の変化。ノイズの可能性。 |
| ノイズ内 | <3%の変化。実質的な差なし。 |
統計的整合性
- チェリーピッキングなし — v1の全シナリオをv2で再実行。全結果を報告。
- 同じデータ生成シード — 両実行で同一の合成ログ。
- 同じマシン — 同一ハードウェアでの両実行。
- ウォームキャッシュ — ウォームアップイテレーションは計測前に破棄。
- リグレッションを正直に報告 — 4つのリグレッションを備考付きでリスト。
残された課題
3つの最適化が最悪のボトルネックに対処した。残るもの:
- Rust検索がフロア — エンジンは
limit適用前に全マッチ結果を収集。真の早期終了検索がサンプリングと大結果クエリを助ける。 format_tree()が遅い — 階層レンダリングに1.7秒。ツリートラバーサル+フォーマッティングの最適化が必要。- Python JSONデシリアライゼーション — 全結果がRust→Python境界をJSON文字列として越え、
json.loads()される。直接のPyO3 dict返却でスキップ可能。 - 永続インデックス — 現在ファイルは初回アクセスで再パース。ディスクベースインデックスでコールドスタートが即座に。
再現
# 両方のベンチマークセットを実行
uv run python -m benchmarks run --scale small --tag v1
uv run python -m benchmarks run --scale small --tag v2
# 比較を生成
uv run python -m benchmarks compare \
-b benchmarks/results/v1/baseline.json \
-c benchmarks/results/latest.json \
-o benchmarks/results/v2 \
--changes benchmarks/results/v2/CHANGES.md
この記事の全チャートと数値はベンチマークスイートから再現可能。