SQLer 注目 
SQLite向けの軽量JSON-firstマイクロORM。PydanticモデルをJSONドキュメントとして保存し、直感的なクエリ、FTS5検索、楽観的ロック、84K行/秒のバルク挿入を提供。
SQLer
SQLite向けの軽量JSON-firstマイクロORM。Pydanticモデル(または軽量なdataclassモデル)をJSONドキュメントとして保存し、直感的なAPIでクエリ。同期・非同期の両方に対応。
なぜSQLer?
SQLiteは世界で最も普及しているデータベースであり、JSON1がドキュメントストアに変える。SQLerはその橋渡し役:Pydanticバリデーションとドキュメント型の柔軟性、ネストしたJSONの中まで探れるクエリビルダー、そして本物のデータ整合性 — 全てが単一ファイル、設定不要のデータベースで動く。
向いている場面: 高速プロトタイピング、組み込みアプリ状態(Electron、CLIツール、モバイル)、Pydanticバリデーション付きのJSON柔軟性、「数時間ではなく数分で動くストレージ」が必要な全ての場面。
クイックスタート
from sqler import SQLerDB, SQLerModel
from sqler.query import SQLerField as F
class User(SQLerModel):
name: str
age: int
tags: list[str] = []
db = SQLerDB.in_memory()
User.set_db(db)
User(name="Alice", age=30, tags=["admin"]).save()
User(name="Bob", age=25, tags=["user"]).save()
admins = User.query().filter(F("tags").contains("admin")).all()
assert admins[0].name == "Alice"
モデルはPydantic — 型ヒント、バリデーション、デフォルト値がそのまま使える。保存は明示的:.save() は _id を付けてselfを返す。クエリは F() 演算子でJSON対応のSQLにコンパイルされる。
2つのモデルバリアント
| バリアント | ベース | バリデーション | 用途 |
|---|---|---|---|
SQLerModel | Pydantic | 完全な型変換+エラーメッセージ | 本番、APIレイヤー |
SQLerLiteModel | @dataclass | なし(高速、依存なし) | ブラウザ/WASM、軽量スクリプト |
LiteモデルはPyodide/WebAssemblyで動作 — Pydantic依存なし、Rustコンパイル不要。クエリAPIは両方で同一。
from dataclasses import dataclass
from sqler import SQLerDB, SQLerLiteModel
@dataclass
class User(SQLerLiteModel):
__tablename__ = "users"
name: str
age: int
パフォーマンス
ベンチマークスイートの実測値(22シナリオ、Python 3.12、SQLite 3.50):
| 操作 | 結果 | コンテキスト |
|---|---|---|
| バルク挿入 | 84K行/秒 | bulk_upsert() 10K行時 |
| インデックス効果 | 470倍 | 9.4ms → 0.02ms(create_index()) |
| キャッシュヒット | 7,000倍 | 14ms → 0.002ms(@cached_query) |
| FTS検索 | 0.28ms | データ規模に関わらずサブミリ秒 |
| バルク vs 単体 | 5.3倍 | bulk_upsert vs save() ループ(10K行) |
| Liteモデル | 1.3倍 | dataclass版 vs Pydanticオーバーヘッド |
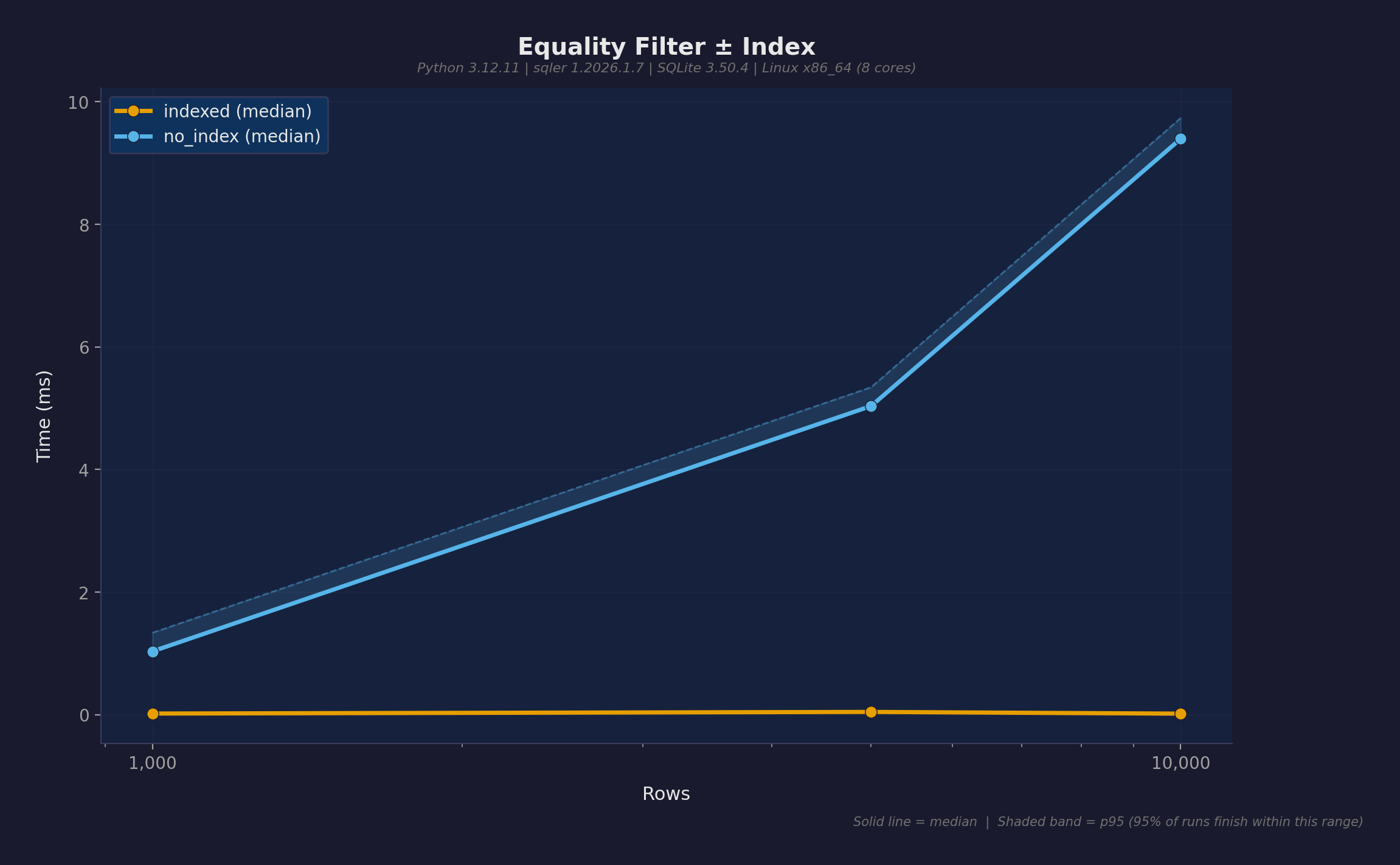
最も重要な最適化:クエリ述語にインデックスを張ること。db.create_index("table", "field") でJSONパスに式インデックスを作成。インデックス付きクエリはテーブルサイズに関係なく~0.02msで安定する。
機能
クエリビルダー
F() 演算子でネストしたJSONへの直感的なフィルタ:
# 等値、比較、ソート
User.query().filter(F("age") > 30).order_by("name").all()
# ネストしたフィールドアクセス
User.query().filter(F("address")["city"] == "Kyoto").all()
# 配列操作
Order.query().filter(F(["items"]).any().where(
(F("sku") == "RamenSet") & (F("qty") >= 2)
)).all()
# 包含、所属、除外
User.query().filter(F("tags").contains("admin")).all()
User.query().filter(F("tier").isin([1, 2])).all()
User.query().exclude(F("name").like("test%")).all()
他にも:between、is_null、is_not_null、startswith、endswith、glob、or_filter、distinct_values、paginate。
リレーション
参照は { "_table": "addresses", "_id": 1 } としてJSONに保存され、ロード時にモデルインスタンスへ水和(hydrate)される:
class User(SQLerModel):
name: str
address: Address | None = None
loaded = User.from_id(user._id)
assert loaded.address.city == "Kyoto" # 自動水和
kyoto_users = User.query().filter(
User.ref("address").field("city") == "Kyoto"
).all()
楽観的ロック
SQLerSafeModel はレコードごとに _version を追跡。競合する更新は StaleVersionError を発生:
from sqler import SQLerSafeModel, StaleVersionError
class Account(SQLerSafeModel):
owner: str
balance: int
try:
account.save()
except StaleVersionError:
account.refresh() # DBから再読込して判断
参照整合性
データベース制約なしの削除ポリシー:
restrict— 参照されている間は削除を拒否set_null— 参照フィールドをクリアしてから削除cascade— 依存レコードを再帰的に削除
author.delete_with_policy(on_delete="cascade")
validate_references() で漏れた孤立参照を検出可能。
全文検索
FTS5ベースの検索、ランキング、ハイライト対応:
from sqler import FTSIndex
fts = FTSIndex(Article, fields=["title", "content"])
fts.create(db)
fts.rebuild()
results = fts.search("Python") # データ規模に関わらず0.28ms
ranked = fts.search_ranked("Python") # BM25関連度スコア付き
snippets = fts.search_highlights("Python") # ハイライト付き抜粋
同期・非同期
同じセマンティクスの並行API。同期でプロトタイプし、FastAPIへ書き換えなしで移行:
from sqler import AsyncSQLerDB, AsyncSQLerModel
async def main():
db = AsyncSQLerDB.in_memory()
await db.connect()
# 同じクエリAPI、awaitするだけ
プロダクション機能
| 機能 | 説明 |
|---|---|
bulk_upsert() | 84K行/秒のバッチ挿入 |
@cached_query | TTLベースの結果キャッシュ(LRU回収) |
MetricsCollector | Prometheus/StatsD形式のクエリ監視 |
PooledSQLerDB | WAL付きスレッドセーフな接続プール |
| エクスポート/インポート | CSV、JSON、JSONL(同期+非同期) |
| スキーママイグレーション | add_field()、remove_field()、rename_field() |
| 変更追跡 | is_dirty()、get_dirty_fields()、TrackedModel |
| トランザクション対応 | with db.transaction(): 内の model.save() は正しくロールバック |
インタラクティブツアー
11本のブラウザベースmarimoノートブック — インストール不要で直接コードを実行・編集:
| ツアー | トピック |
|---|---|
| 01. 基礎 | モデル、CRUD、クエリ、集計 |
| 02. リレーション | 参照、水和、モデル間クエリ |
| 03. セーフモデル | 楽観的ロック、競合解決 |
| 04. トランザクション | アトミック操作、ロールバック |
| 05. Mixin | タイムスタンプ、論理削除、ライフサイクルフック |
| 06. 上級 | バルク操作、インデックス、整合性、生SQL |
| 07. エクスポート/インポート | CSV、JSON、JSONL |
| 08. 全文検索 | FTS5、ブール検索、ランキング |
| 09. 変更追跡 | ダーティチェック、変更検出 |
| 10. DB操作 | ヘルスチェック、統計、VACUUM、ログ |
| 11. メトリクス・キャッシュ | Prometheusメトリクス、クエリキャッシュ、プール |
全11本がPyodide/WASM上でLiteモデルを使ってブラウザ内で動作。Pydanticフル版はローカルで uv run marimo edit examples/tour_01_fundamentals.py。
正直な制限事項
- シングルライター — SQLiteのアーキテクチャ。
bulk_upsertとトランザクションで書き込みをバッチ化。 - JSONオーバーヘッド — フィールドは
json_extract()経由。ネイティブカラムではない。インデックスで差を埋める。 - JOINなし — リレーションは参照水和で解決。SQL JOINではない。典型的なドキュメントパターンには十分。
- メモリ制約 — 大きな結果セットはPython上に展開される。
paginate()とcount()で制限を。
はじめる
pip install sqler # または: uv add sqler
Python 3.12+ · JSON1付きSQLite(ほとんどのプラットフォームで同梱)。
uv run pytest -q # 548テスト
uv run python -m benchmarks run # 22ベンチマークシナリオ
English: Read this project in English