Logler 注目 
Rust駆動のローカルログ構造化調査ツール。AIエージェント最適化。5サービスのクロスサービスタイムライン13ms、50Kエントリでの階層構築349ms、25のJSON CLIコマンド。
Logler
Rust駆動のローカルファイルからの構造化ログ調査ツール。ログファイルを指定すれば、何が起きたかを構造化された回答で返す。AIエージェント向けに最適化 — 全コマンドがJSONを返し、全出力がトークンバジェットに収まる。
なぜLogler?
grepとDatadogの間にギャップがある。grepは文字列を見つけるが、サービス間で何が起きたかは教えてくれない。ELK/Loki/Datadogはインフラ、インジェストパイプライン、継続的なコストが必要。ほとんどのデバッグセッションは、ローカルのログファイルと「何がおかしい?」という問いから始まる。
Loglerはそのギャップを埋める。ローカルファイルをパースし、メモリ内インデックスを構築し、構造化された質問に答える — ターミナルを離れることなく。
向いている場面: インシデントデバッグ、AIエージェント向けログトリアージ、インフラなしのクロスサービス相関、ログファイルがあって素早く答えが必要な全ての場面。
クイックスタート
from logler.investigate import search, follow_thread, extract_ids
# 構造化フィルタで検索
result = search(["app.log"], query="timeout", level="ERROR,WARN", limit=50)
print(f"Found {result['total_matches']} matches")
# スレッドをファイル横断で追跡
thread = follow_thread(["app.log", "worker.log"], thread_id="req-42")
for entry in thread["entries"]:
print(f"{entry['timestamp']} [{entry['level']}] {entry['message']}")
# 探索用に全IDを抽出
ids = extract_ids(["app.log"])
print(f"{len(ids['thread_ids'])} threads, {len(ids['services'])} services")
Rustがファイルをパースしインデックスを構築。Pythonが調査APIを提供。全関数がtypes.pyで文書化された型付きdictを返す。
アーキテクチャ
三層設計 — 各層が得意なことを担当:
Rust コア (4.3K LOC) — パース、インデックス、検索、階層構築
PyO3 ブリッジ — RustとPython間のゼロコピーFFI
Python レイヤー (14.2K LOC) — 相関、サンプリング、メトリクス、CLI
Rustコアがフォーマット検出(JSON、syslog、logfmt、プレーンテキスト)、フィールド抽出、検索を担当。Pythonは柔軟性が必要なアルゴリズムを実装:相関エンジン、サンプリング戦略、メトリクス抽出、フォーマット検出、テンプレートマイニング。
薄いラッパーではない。Rustコアは本物のパースとインデックスを行い、Pythonレイヤーは本物のアルゴリズムを持つ。DuckDB/SQLは220行のオプションのエスケープハッチ。
パフォーマンス
ベンチマークスイートの実測値(14シナリオ、Python 3.12、Rustバックエンド):
| 操作 | 結果 | コンテキスト |
|---|---|---|
| 階層構築 | 349ms | 50Kエントリ(最適化前は86秒) |
| クロスサービスタイムライン | 13ms | 5サービス相関 |
| エラーフロー分析 | <2ms | 完全なエラー伝播ツリー |
| スレッド追跡 | 148ms | 50Kエントリ |
| トークン節約 | 2,540倍 | count vs full 出力フォーマット |
| スマートサンプリング | 196ms | 10Kエントリ、50サンプル |
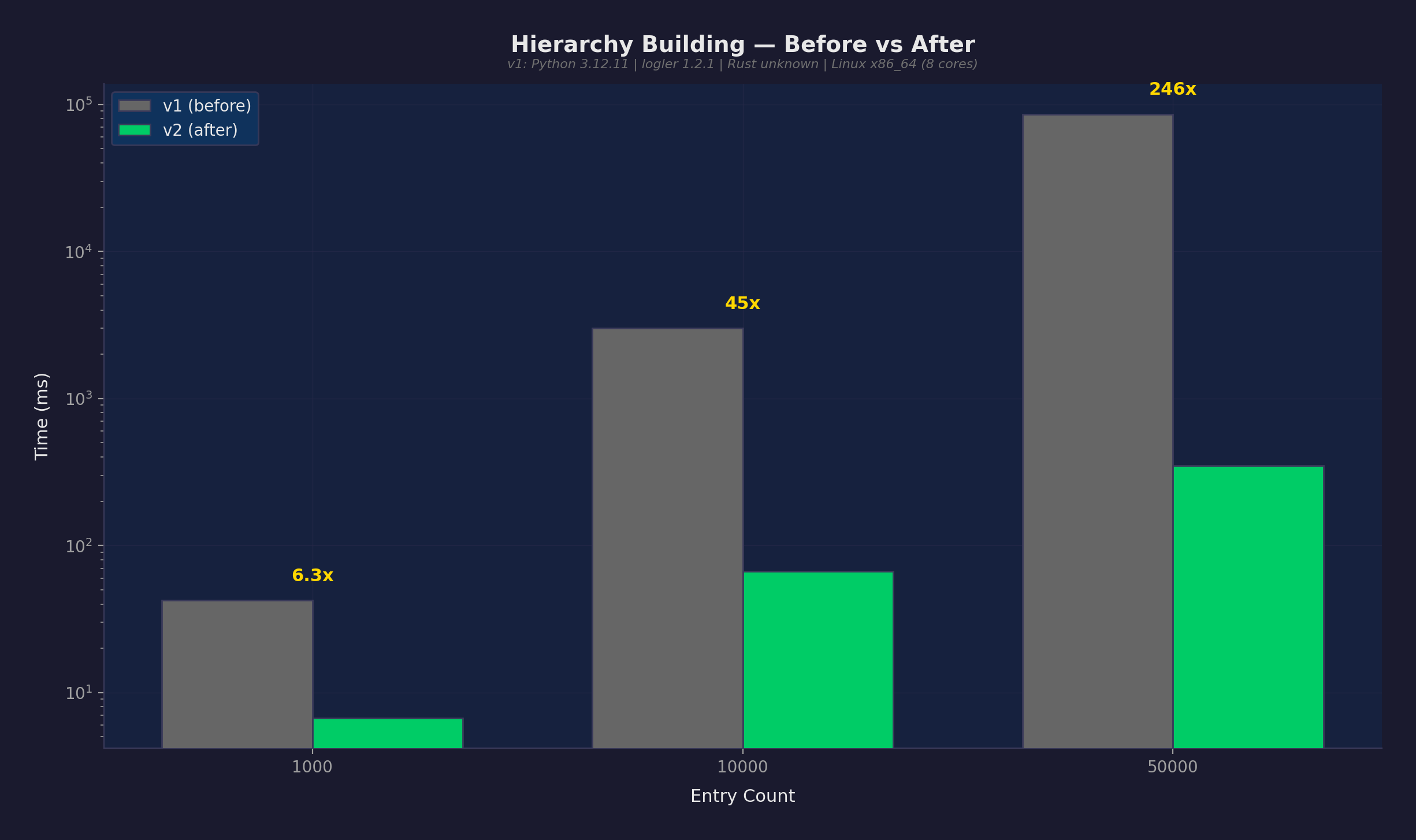
最もインパクトの大きい最適化:階層命名推論のBTreeSetプレフィックスインデックス。O(n^2)の線形スキャンをO(log n + k)の範囲クエリに置き換え。50Kエントリで階層構築が86秒から349ミリ秒に。
機能
25のJSON CLIコマンド
全コマンドが構造化JSONを返す。stdoutのパースも、人間可読出力への正規表現も不要。LLMエージェント専用設計:
# トリアージ — 何がおかしい?
logler llm triage app.log worker.log
# トークンバジェット付き検索
logler llm search app.log --level ERROR --max-bytes 4096
# クロスサービス相関
logler llm correlate app.log worker.log --thread-id req-42
# 階層 — 親子スレッド関係
logler llm hierarchy app.log --root worker-1
クロスサービスタイムライン
スレッドID、相関ID、トレースIDを使ってサービス間で何が起きたかを再構築:
from logler.investigate import cross_service_timeline
timeline = cross_service_timeline(
["api.log", "worker.log", "db.log"],
correlation_id="req-42"
)
スマートサンプリング
大規模ログファイル向けのインテリジェントサンプリング — 全て読まずに代表的なサンプルを取得:
from logler.investigate import smart_sample
sample = smart_sample(
["app.log"],
strategy="errors_focused",
sample_size=50
)
スレッド階層
命名パターン(worker-1 -> worker-1.task-a)、スパンID、相関チェーンから親子関係を構築。
トークンバジェット制御
全検索コマンドが --max-bytes をサポートし、LLMのトークンバジェット内に出力を収める。countフォーマットで2,540倍のトークン節約。
その他
| 機能 | 説明 |
|---|---|
| メトリクス抽出 | 数値抽出、統計、z-score異常検出 |
| テンプレートマイニング | Drainアルゴリズムによるログテンプレート発見 |
| エラーフロー分析 | サービス階層でのエラー伝播追跡 |
| ボトルネック検出 | トレース内の最遅スパン特定 |
| SQLエスケープハッチ | 必要時のDuckDBアドホッククエリ |
| イベント相関 | タイムウィンドウ付きクロスファイルイベント相関 |
| セッション管理 | ノート付きステートフル調査セッション |
| エクスポート | Jaeger/Zipkinトレースフォーマット出力 |
正直な制限事項
- 永続インデックスなし — ファイルはセッションごとに最初のアクセスで再パース。LRUキャッシュで繰り返しクエリの再パースは回避するが、ディスクベースのインデックスはない。
- 単一マシン — ローカルファイル向け設計。分散ログ収集ではない。これは制限ではなくポイント — マルチマシンインジェストが必要ならLokiを使うべき。
- Rust検索がフロア — Rustエンジンは
limitで切り詰める前に全マッチ結果を収集する。limit=10のクエリでも内部では全エントリをスキャン。 - サンプリングのボトルネック — 50Kエントリではサンプリングに6秒以上かかる。Rust検索コストが支配的(サンプリングアルゴリズムではない)。
はじめる
pip install logler # または: uv add logler
Python 3.12+、Rustバックエンド(Linux/macOS向けプリコンパイルホイール)。
uv run pytest -q # 1,064テスト
uv run python -m benchmarks run # 14ベンチマークシナリオ
English: Read this project in English